개념 및 이론
###데이터베이스 (DB, DataBase)
- 정의
- 여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합. 여러 응용 시스템들의 통합된 정보들을 저장하여 운영할 수 있는 공용 데이터들의 묶음
- 도입 배경
- 독립된 파일 단위로 데이터를 저장하게 되면 데이터 종속성 및 중복성이 높아 무결성을 위배할 가능성이 높을 수 있기에 이를 보안하고자 여러 시스템이 공용으로 데이터를 모아 관리하는 데이터 베이스를 구축
- 필수 보안 요소
- 무결성(integrity): 자료에 오류가 없어야 함. 최초에 오류가 없더라도 추가,갱신,삭제 등으로 오류가 발생 가능한데, 권한자만 자료를 수정이 가능하도록 해야 한다.
- 가용성(availability): 권한을 가진 사용자가 데이터베이스에 접근할 수 있도록 하는 것. 즉, 권한자의 접근을 거부하면 안된단 뜻. 가용성이 없으면 권한자나 프로그램이 자료사용이 불가한 경우가 발생함
- 기밀성(confidentiality): DBMS가 기술적으로 외부위협으로부터 자료 기밀을 보호해야 한다는 뜻. 기밀성은 권한없는 사용자에게 자료노출을 방지하는 기능
관계형 데이터베이스 (RDB)
- 정의
- RDB : Relational DataBase
- 데이터 관계형 모델에 기초하는 데이터베이스.
- 키(key)와 값(value)들의 간단한 관계를 테이블화 시킨 오늘 날 대표적인 데이터베이스로 자리 잡은 매우 간단한 원칙의 전산정보 데이터베이스.
- 관계형 데이터모델 (Relational datamodel)
- 데이터 검색 시 뒷따르는 링크가 아닌 내용을 기준으로 데이터를 검색해야 한다고 주장하면서 만들어진 모델.
- 데이터 모델 중에서 가장 개념이 간단한 모델. 데이터를 컬럼(column)과 로우(row)를 이루는 하나 이상의 테이블(또는 관계)로 정리하며, 고유 키(Primary key)가 각 로우를 식별.
- 일반적으로 각 테이블/관계는 하나의 엔티티 타입(고객이나 제품과 같은)을 대표
관계형 데이터베이스 관리 시스템 (RDBMS)
- 정의
- RDBMS : Relational DataBase Management System
- 관계형 데이터모델을 한곳에 모은 저장소를 만들고 그 저장소에 여러 사용자가 접근하여 데이터를 저장 및 관리 등의 기능을 수행하며 공유할 수 있는 환경을 제공하는 응용 소프트웨어 프로그램.
- 공유 저장소(서버)를 구축하고 사용자들에게 접근정보를 공유하여 데이터를 처리할 수 있는 인터페이스를 제공하고 복구기능과 보안성 기능 또한 제공
- SQL(Structured Query Language, 구조화 질의 언어)
- 관계형 데이터베이스를 이용하기 위한 표준 언어
- 고도로 정교한 검색 쿼리를 제공하며 상상하는 거의 모든 방식으로 데이터를 다룰 수 있게 해줌
- 비-관계형 데이터베이스 : NoSQL (정식 명칭 : 객체형, 문서형, 컬럼형 등)
- 대표적인 RDBMS : Oracle, MySQL, SQL Server, …
- (R)DBMS의 기능 및 언어
- 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 데이터 처리 기능인 CRUD 제공. (CRUD : Create, Read, Update, Read)
- 정의어(DDL, Data Definition Language) : DB를 생성하거나 자료 형태(type)와 구조 등을 수정하며 데이터를 이용하는 방식을 정의하는 기능 [CREATE, ALTER, DROP]
- 조작어(DML, Data Manipulation Language) : 데이터의 검색, 삽입, 삭제, 변경 등을 처리하는 기능 [SELECT, INSERT, DELETE, UPDATE]
- 제어어(DCL, Data Control Language) : 데이터의 무결성을 유지하기 위한 보안 및 권한 검사, 병행 제어 등의 기능을 정의하는 기능 [COMMIT, ROLLBACK, GRANT, REVOKE]
 이미지출처:
이미지출처: 실습 (MySQL)
※ 본 실습은 프로그래머스의 SQL고득점 Kit를 기반으로 작성하였습니다.
DataBase Basic
- 데이터베이스 생성 : CREATE DATABASE db;
- 데이터베이스 삭제 : DROP DATABASE db;
- 데이터베이스 목록 확인 : SHOW DATABASES;
- 데이터베이스 선택 및 사용 : USE db;
- 선택한 데이터베이스 속 테이블 확인 : SHOW TABLES;
-
선택한 데이터베이스 속 테이블 생성
CREATE TABLE topic( id INT(11) NOT NULL AUTO_INCREMENT, title VARCHAR(100) NOT NULL, description TEXT NULL, created DATETIME NOT NULL, author VARCHAR(30) NULL, profile VARCHAR(100) NULL, PRIMARY KEY(id) -- 변수명 DataType(size) AllowNullOrNot auto_increment -- PRIMARY KEY(변수명) );- DataType(size) : 사용에 따른 자료형 설정. size는 최대 크기
- AllowNullOrNot
- NOT NULL : 해당 COL의 값이 NULL이면 안된다는 뜻
- NULL : 해당 COL의 값을 비워둬도 괜찮다는 뜻
- AUTO_INCREMENT : 값 자동 설정
- PRIMARY KEY(변수명) : 기준이 되는 변수 설정. → 성능향상 및 중복방지 역할
- 테이블의 Column 정보 확인 : DESC topic;
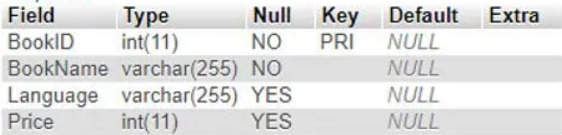
CRUD (Data in Table)
- CREATE (Data 생성)
-
INSERT INTO .. (,,) VALUES (,,)
INSERT INTO topic (title, description, created, author, profile) VALUES ('MySQL', 'RDBMS', NOW(), 'PARK', 'IBM developer');
-
- UPDATE (Table 속 Data 수정)
-
UPDATE .. SET ..
UPDATE topic SET title='ORACLE', description='Relational DBMS' WHERE title='MySQL'; -- title이 MySQL인 놈을 해당 setting으로 변경.
-
- DELETE (Table 속 Data 삭제)
-
DELETE FROM ..
DELETE FROM topic WHERE id=1; -- id가 1인놈을 삭제.
-
- READ (Table 속 Data 읽기)
- SELECT .. FROM ..
- SELECT * FROM topic; # 전체 데이터 불러오기
- SELECT id,title FROM topic; # 전체 데이터 중 일부 COL만 가져오기
- SELECT * FROM topic WHERE author=’PARK’; # 일부 데이터만 가져오기
-
일부 데이터 내림차순으로 정렬한 후 상위 2개만 표시
SELECT * FROM topic WHERE author="PARK" ORDER BY id DESC LIMIT 2;
- SELECT .. FROM ..
ETC (ORDER BY, WHERE, GROUP BY, JOIN, …)
-
ORDER BY
SELECT * FROM ANIMAL_INS ORDER BY ANIMAL_ID; #DESC- 정렬하여 출력(READ)할 때 사용
- Default는 오름차순. 내림차순 사용 시 DESC 필수.
- 여러 기준으로 정렬 시, 우선순위 순으로 작성 예를 들어, 이름 순으로 정렬하고 이름이 같을 땐, 날짜로 정렬한다고 하면 → … ORDER BY NAME, DATETIME;
- 정렬 후 상위 N개 표시 → LIMIT N; → … ORDER BY NAME LIMIT 1;
- 계산 결과를 통해 정렬 → … ORDER BY O.DATETIME - I.DATETIME DESC;
-
WHERE
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS WHERE INTAKE_CONDITION ="Sick"- 데이터를 가져올 때 조건을 달아주는 것. 여타 다른 코딩에서의 IF 절과 같은 느낌.
- WHERE 뒤에 NOT 즉, WHERE NOT 은 if not 과 같은 역할. ‘!()’ 느낌
-
데이터의 요소 COL 중 null이 아닌 데이터 가지고 오기 (where .. is not NULL)
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS WHERE NAME is not NULL;-
NULL 처리 하기 [ IFNULL( COL, 대체할 값 ) ]
SELECT ANIMAL_TYPE, IFNULL(NAME, 'No Name') FROM ANIMAL_INS;
-
-
조건 여러 개 두기. (and, or)
SELECT hour(DATETIME), count(DATETIME) FROM ANIMAL_OUTS WHERE hour(DATETIME) >= 9 and hour(DATETIME) < 20 GROUP BY hour(DATETIME) ORDER BY 1; -
여러가지 조건에 해당하는지 판단 → WHERE .. IN (…)
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS WHERE NAME in ('Lucy', 'Ella', 'Pickle', 'Rogan', 'Sabrina', 'Mitty'); -
값에 해당 문자, 문자열이 들어가는지 판단 → like ‘%%’
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS WHERE NAME LIKE '%el%' -- 이름에 'el' 이 들어간 놈
- CASE WHEN .. THEN .. ELSE .. END
- 정해진 조건에 맞게 원하는 표현으로 출력하고 싶을 때
- 조건은 WHERE이 아닌 WHEN 사용
- 추가로 THEN, ELSE로 조건에 맞을 때와 틀릴 때를 구분
- END로 CASE 절 마무리
SELECT ANIMAL_ID, NAME, CASE WHEN SEX_UPON_INTAKE LIKE '%Neutered%' or SEX_UPON_INTAKE like '%Spayed%' THEN 'O' ELSE 'X' END as '중성화' FROM ANIMAL_INS; -
MAX/MIN/COUNT/SUM
SELECT MAX(DATETIME) FROM ANIMAL_INS SELECT MIN(DATETIME) FROM ANIMAL_INS SELECT COUNT(*) FROM ANIMAL_INS SELECT SUM(MONEY) FROM ACCOUNT$$ 이런 내장 함수들은 Group에 적용됨! → Group BY를 하지 않으면 하나의 그룹.
- MAX
- 선택된 데이터들의 COL 중 가장 큰값을 나타냄
- ORDER BY .. DESC LIMIT 1; 로도 표현 가능
- FROM 이후에 사용하는 것이 아닌 SELECT에서 사용
- MIN도 사용방법 똑같, 개념만 반대
- COUNT
- 조건에 맞는 데이터의 개수를 셈
- FROM에서 WHERE 등 조건에 맞게 걸러 왔다면 COUNT(*) 를 통해 걸러온 전체 데이터의 수를 셈
-
요소들 중 중복을 제거하고 COUNT하기 → COUNT(DISTINCT NAME)
SELECT COUNT(distinct NAME) FROM ANIMAL_INS WHERE NAME is not NULL;
- SUM
- 모든 데이터에서의 해당 요소의 합
- MAX
-
GROUP BY
SELECT ANIMAL_TYPE, COUNT(*) FROM ANIMAL_INS GROUP BY ANIMAL_TYPE- 그룹화하여 데이터 조회
- 유형별로 갯수를 알고 싶을 때는 컬럼에 데이터를 그룹화 할 수 있는 GROUP BY를 사용
- GROUP BY 를 통해 그룹화 진행 후 조건을 달고 싶다면 즉, 각각의 그룹 자체로 걸러내고 싶다면 WHERE이 아닌 HAVING 사용.
- GROUP BY 후 ORDER BY 할 때는 GROUP BY에 사용된 변수로 정렬 시 그 변수의 순서를 통해 표시할 수 있음
SELECT NAME, count(*) FROM ANIMAL_INS WHERE NAME is not NULL GROUP BY NAME HAVING COUNT(*) >= 2 ORDER BY 1; # or NAME※ 그룹화 이전, 데이터를 거르고 싶다 → WHERE
※ 그룹화 이후, 그룹 자체로 판단하여 데이터를 거리고 싶다 → HAVING
-
JOIN
SELECT A.[] FROM TALBLE_A (as) A [ ] JOIN TABLE_B (as) B ON A.KEY = B.KEY ...- FROM .. [ ? ] JOIN .. ON ..
- ON 으로 설정한 COL을 기준으로 A와 B가 합쳐지는 것.
- 해당 key로 가로로 합쳐짐!!
-
두 테이블을 결합할 때 사용. 혹은 이를 통해 두 테이블의 차이, 공통 요소 등을 찾을 때 사용.
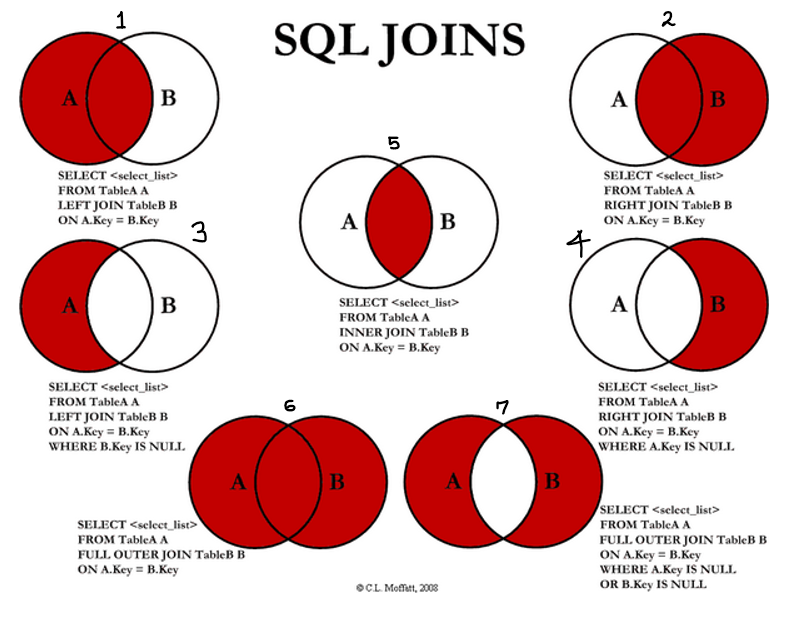
%% 항상 문제가 있을 때, 문제 조건을 위의 다이어그램을 통해 판단하면 됨. 또한, 항상 연결된 테이블을 떠올리면 판단하면 됨.
- LEFT : 왼쪽(FROM)을 중심으로 보겠다. RIGHT : 오른쪽(FROM에 JOIN하는 애)을 중심으로 보겠다.
- A에 B 연결하기 → A값의 전체와, A의 KEY 값과 B KEY 값이 같은 결과를 리턴, A에 해당하는 B값이 없다면 A에 NULL값으로 표시됨. → A연결되지 않는 B는 보이지 않음.
- B에 A 연결하기 → B값의 전체와, B의 KEY 값과 A KEY 값이 같은 결과를 리턴, A에 해당하는 B값이 없다면 A에 NULL값으로 표시됨. → B연결되지 않는 A는 보이지 않음.
- A에 B 연결 후 ‘B에는 없고 A에만 있는 놈 찾기’ → B.key is NULL
- B에 A 연결 후 ‘A에는 없고 B에만 있는 놈 찾기’ → A.key is NULL
- A와 B 모두에 있는 놈 찾기 (교집합) → INNER JOIN JOIN 후 not NULL 로 찾을 수도 있음
- 그냥 모든 놈들을 연결해서 출력 (없는 놈들은 없는놈대로 출력) → FULL OUTER JOIN
- 모든 놈들을 연결한 후 ‘겹치는 놈들 제거’ → A.key is null OR B.key is null
- FROM .. [ ? ] JOIN .. ON ..
- 유용한 함수 및 기능
- 날짜 관련 함수 모음
- year(DATETIME) : 해당 날짜의 년도를 알려줌.
- month(date) : 해당 날짜가 몇 월인지 알려줌.
- hour(DATETIME) : 해당 날짜의 시간을 알려줌
- minute(DATETIME) : 해당 날짜의 분을 알려줌.
- second(DATETIME) : 해당 날짜의 초를 알려줌.
-
date_format(DATETIME, ‘%Y-%M-%D’) : 원하는 날짜 형식으로 출력하기
- week(date) : 해달 날짜가 몇 번째 주일인지(0 ~ 52)를 리턴
- weekday(DATETIME) : 날짜를 한 주의 몇 번째 요일인지를 나타내는 숫자로 리턴
- dayofmonth(DATETIME) : 그 달의 몇 번째 날인지를 알려줌. 리턴 값은 1에서 31 사이
- dayofyear(DATETIME) : 한 해의 몇 번째 날인지를 알려줌. 리턴 값은 1에서 366 사이
- dayname(date) : 해당 날짜의 영어식 요일 이름 반환
- SQL 속에서 재귀함수를 통해 새로운 테이블 생성
-
WITH RECURSIVE [ 테이블이름(변수) ] as ( … )
with recursive time(hour) as( select 0 -- hour의 초깃값 union all -- 해당 코드의 결과를 계속 합치겠다는 뜻 select hour + 1 from time where hour < 23 -- 해당 time 테이블에서 조건에 맞게 hour를 가져온 후 +1 ) -- -> 0~23 값을 가지는 테이블 생성됨 SELECT hour, count(animal_id) from time t left join animal_outs a on hour = hour(a.datetime) group by hour
-
- 날짜 관련 함수 모음
참고
개념 설명 잘되어 있음. 나중에 공부할 때 참고 → 나무위키-DB