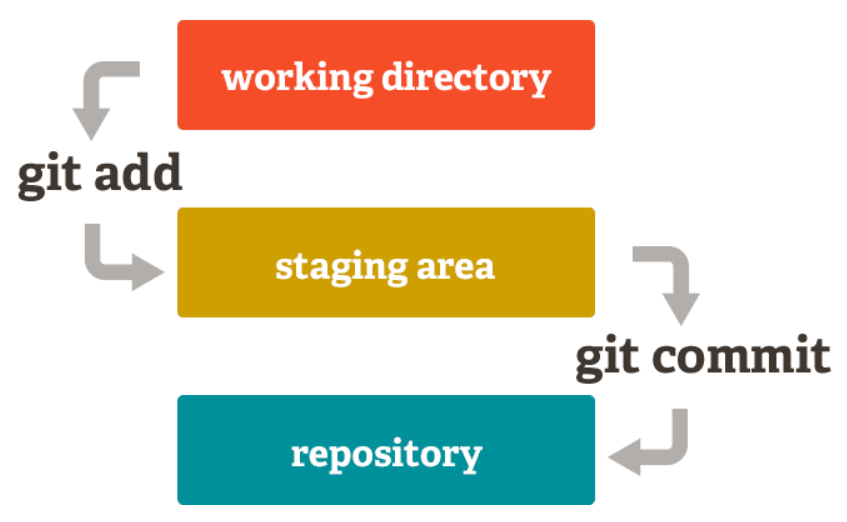
Git을 왜 사용해야 하나?
- Git
- 정의 : 컴퓨터 파일의 변경사항을 추적하고 여러 명의 사용자들 간에 해당 파일들의 작업을 조율하기 위한 분산 버전 관리 시스템 또는 이러한 명령어. 어떠한 집합의 파일의 변경사항을 지속적으로 추적하기 위해 사용.
- 사용 목적
- 버전 관리 : 동일한 정보에 대한 여러 버전을 관리하는 것. Version을 통해서 시간적으로 변경 사항과 그 변경 사항을 작성한 작업자를 추적할 수 있음. 이는 버전들의 기록을 통해 이전 버전의 기능을 다시 가져오거나, 잘못된 코드에 대한 복원이 필요하기에 사용됨.
- 협업 : 큰 규모의 프로젝트를 진행하게 되면 다수의 개발자들과의 협업이 필요할 때가 있음. 협업은 하나의 공유 가능한 Repository 안에서 다수의 개발자들이 각자 맡은 파트를 공유하며 작업하고, 해당 작업사항을 업데이트하고, 서로의 작업 로그를 살펴볼 수 있어야 하며, 이에 더해 버전별 백업도 실시간으로 진행되어야 함. 이런 여러 가지를 Git을 통해 수행할 수 있음. ( → 버전 관리) 협업은 작업 중 실시간으로 작업내역을 공유되는 원격저장소가 필요하며 이는 Git으로 가동이 되는 깃 저장소 GitLab, Github을 통해 수행 가능.
- 제공 GUI : Sourcetree, GitHub Desktop 등의 여러 GUI 사용 가능
- 터미널 인터페이스 : Git Bash ( 윈도우에서 linux나 unix같은 운영체제에서 사용하는 명렁어 형태를 윈도우에서 사용할 수 있게 해주는 프로그램 )
버전관리의 본질 [Code]
기본 설치 및 세팅
- Git 공식 Document : Docs
- 명령어
git init: 버전관리를 하고자 하는 directory를 git에게 알려주기 → [start a working area → init] (가장 초기 작업)- init : 현재 위치의 디렉토리에 작업을 진행하겠다는 것을 git에게 알려주는 역할 (내부 저장소 이용)
- init 해주면 .git 이라는 파일이 생긴 것을 확인할 수 있음 → .git : 버전관리 시 여러가지 정보들(버전 정보, … )이 기록되는 저장소. (삭제하게 되면 마지막 파일은 유지가 되겠지만, 이전의 파일에 대한 정보들이 사라지게 됨.)
vim EDITOR: 파일 생성 및 수정, 읽기가 가능한 editor.- 명렁어 시스템 대부분에 설치되어 있기에 접근성 용이
- But, 다루기가 까다로움
- 파일 생성 : vim 파일명.확장프로그램
- 입력 모드 : i or a → INSERT
- 모드 나가기 : esc
- vim에서 나가기 : ‘:’ + ‘wq’ (저장하고 나가기)
- 파일 읽기 : cat 파일명.확장프로그램
git status: git이 관리하는 directory에 있는 파일들의 상태를 알려줌 (버전 관리 전, 제일 익혀야 될 명령어)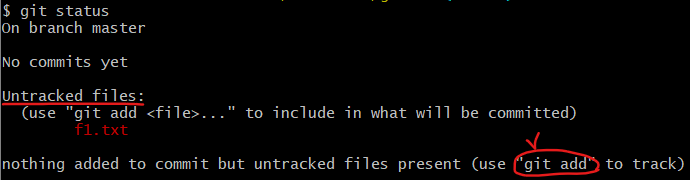
- untracked files : git에게 관리하라고 하지 알려주지 않아 관리가 되고 있지 않은 파일들.
git add: git에게 지정 파일을 버전관리하라고 명령하는 명령어. 즉, 새로 추가한 데이터는 git에게 이를 추적하라고 명확하게 지시를 내려야 됨. 혹은 추적하고 있는 상태에서 수정된 데이터 또한 이를 관리하라고 명확하게 지시해야 됨.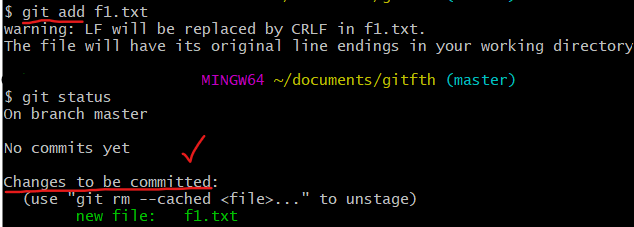
- git이 자동으로 생성된 파일을 추적하지 않는 이유:
→ 프로젝트를 진행한다고 할 때, 그 프로젝트에서 핵심 파일이 있을 것이고, Test를 진행하는 등, 부가적인 중요하지 않은 파일들이 존재하기에 그런 중요하지 않은 파일들은 따로 추적하지 않게 하기 위해 따로 add를 통해 관리할 파일들을 명확하게 지정해 주는 것!
- git이 자동으로 생성된 파일을 추적하지 않는 이유:
본격적인 버전 관리
- Version : 작업의 완결된 상태. 즉, 의미 있는 변화의 결과물을 일컫는 것.
- 관리 전 세팅 : 해당 작업물이 내 것이라는 명시가 필요함. (이름과 이메일) (한번만 하면 됨)
git config --global user.name “사용자명”git config --global user.email “사용자이메일”
git commit: 버전 생성- 입력하면 vim editor가 실행됨. 즉, vim의 기능을 사용하도록 설정됨
- ‘#’ 으로 되어 있는 내용들은 status와 같이 현 상태의 정보들을 알려주는 것.
- 여기다 version의 정보를 알려줘야 함! → version의 메시지를 적어줘야 함! → commit message(version message) → 즉, 이 변화가 어떤 변화를 담고 있는지, 이 변화가 왜 변경되었는지 이유를 적는 것.
- vim editor로 작업하게끔 설정되어 있기에, i를 눌러 insert를 통해 commit message를 적어주고 esc 눌러 모드를 종료하고 :wq 를 통해 저장 후 종료라는 명령을 내려줌.
- 이렇게 하면 이런 결과를 얻게 됨. → commit 되었다. version 생성이 완료 되었다! 는 뜻.
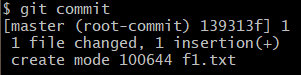
-
git log: 현재 version이 무엇이고 잘 만들었는지 확인하기
%git commit -m ‘원하는 메시지’를 통해 vim editor 없이 commit도 가능 - 파일 변경 후 커밋하여 버전 관리 해보기
vim f1.txt를 통해 f1.txt를 수정git status를 통해 현재 directory의 파일들의 상태 정보를 확인 (tracked 인지, unstracked 인지, modified 인지, … )
git add를 통해 변경된 파일을 버전 관리에 들어가라고 명시.
%git add는 일종의 Context(staging area)라고 생각하면 됨. 내가 현 시점에서 어떤 것을 버전 관리를 할 것이라는 걸 명시하는 역할. 그래서 최초로 추적할 때도, 수정 후 버전을 만들기 전에도 add를 해주는 것!- 다시
git status를 통해 해당 파일이 잘 추적이 되어 Context(staging area)안에 포함이 되어 있는 지 확인.
- 마지막으로
git commit을 통해 해당 context 안에 들어가 있는 파일들의 버전을 생성하라고 명시 → 이때, 버전 정보 즉, commit message를 vim editor를 통해 작성해줌. git log를 통해 버전 관리가 잘 되어 있는지 확인.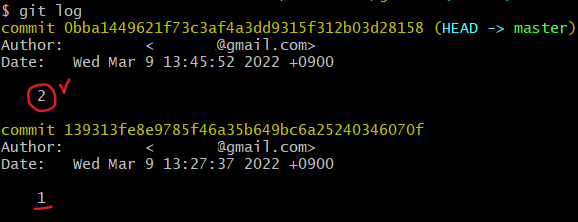
- 왜 Git은 add라는 과정을 포함하고 있는가? (STAGE AREA)
- 선택적으로 파일을 commit 하기 위함
- 만약 굉장히 거대한 프로젝트를 진행하고 있다면, 내가 현재까지 진행한 파일 중 유의미한 변경이 이루어져, 버전을 업데이트하고 싶은 파일이 있는 반면, 아직 제대로 된 변경이 이루어지지 않은 파일이 있을 것 (즉, 아직 반영하고 싶지 않은 결과물). 여기서 만약 add라는 것이 없고, commit만이 존재한다면 이 모든 파일들은 버전으로 관리가 됨. 이런 상황을 대비하여 add가 존재.
- 즉, 선택적으로 유의미한 변경이 이루어진 새로운 버전만을 commit하기 위해 add라는 것이 존재!
- 즉, add를 통해 commit 대기 상태로 만들어 놓는 것.
- add를 한번도 안한 file → untraked. 즉, 아예 stage area에 넣지 않은놈 (넣어야 commit 가능, untraked는 git에서 제공하는 것을 대부분 사용할 수 없음)
- add를 한번 했지만 변경되거나 삭제된 놈 → traked 이지만 변경된 것을 감지하고 이를 stage area에 반영을 할 것인지 확인. (반영해야 commit 가능)
- 즉, add를 통해 git이 commit 하기 위해 대기하고 있는 그 stage area 안 으로 파일을 포함(추적)하게 하는 것!
- 이런 context가 바로 “stage area”
- stage vs repository
- stage : commit 대기 상태의 파일들이 머무르는 곳
- repository : commit이 된 결과가 저장되는 곳
- % 하지만, 선택적으로 add를 할 필요가 없다 라고 하면 그냥
git commit -a를 통해 add 없이 수정되거나 삭제,추가된 모든 파일에 대한 commit을 진행할 수 있음. (but, 한번도 버전 관리가 되지 않은 파일에 대해선 적용 불가. 즉, 처음 add하는 놈은 git add를 통해 진행해야됨.)
- 버전관리에 따른 이점 확인하기 (log, diff)
- 버전에 따른 차이점, 과거의 임의의 시점의 내용을 확인할 수 있음
git log -p: commit 과 commit 간의 소스 상의 차이 확인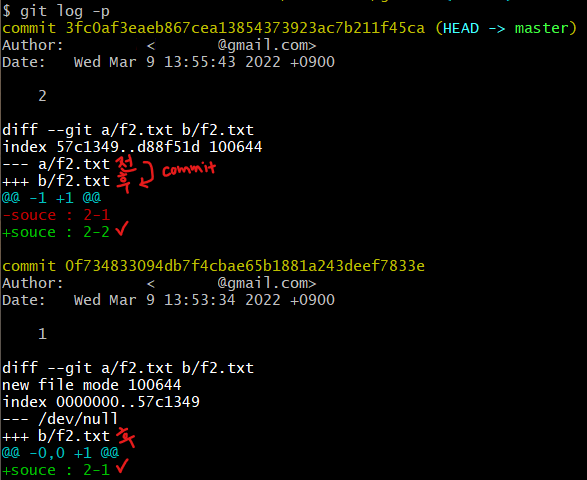 이전 commit 1과 현재 commit 2와의 차이점을 보여주는 log.
이전 commit 1과 현재 commit 2와의 차이점을 보여주는 log.
---: 이전 commit ||+++: 현재 commit commit 옆의 코드는 각 commit의 고유주소. → git log 고유주소 라는 명령어는 해당 commit 의 고유주소를 포함한 이전 log들만을 보여주라는 것.
commit 옆의 코드는 각 commit의 고유주소. → git log 고유주소 라는 명령어는 해당 commit 의 고유주소를 포함한 이전 log들만을 보여주라는 것.- commit을 지정하여 차이 확인
git diff ‘commit1의 고유주소’..’commit2의 고유주소’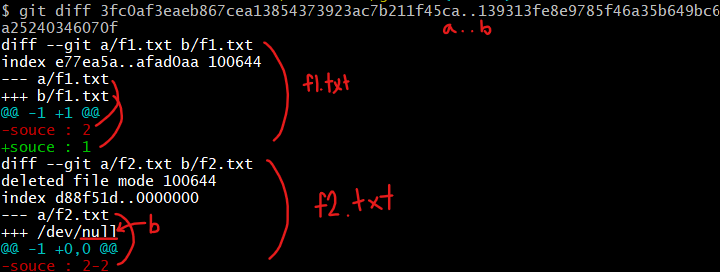
- 각각에 대한 log는 commit된 파일들을 기준으로 나타남.
- git diff commit a .. commit b 로 a 와 b의 내용들을 보여줌
git diff: 현재 내가 어떠한 작업을 했는지를 commit 전에 확인 가능 (stage area(add) 에 들어가기 전에만 가능)
- 과거로 돌아가기 (reset, revert)
- commit을 취소하는 명령
- 내가 이전에 했던 commit으로 다시 돌아가고 싶다 → reset vs revert
- 말그대로 다시 돌아가는 것이기에 신중히 사용해야 됨.
- reset
git reset ‘commit 고유주소’ --hard
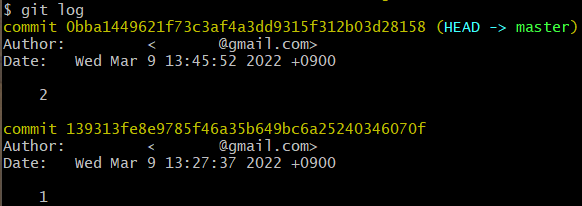 → 해당 고유주소를 가지는 commit으로 돌아감. 즉, 그 이후의 commit들은 삭제되는 것.
→ 해당 고유주소를 가지는 commit으로 돌아감. 즉, 그 이후의 commit들은 삭제되는 것.
→ 사실, git은 그 어떠한 것도 버리지 않음. 즉, 이후의 commit들은 삭제되는 것이 아닌, 보이지 않게 만든 것. 즉, 복구 가능 (But, 복잡..)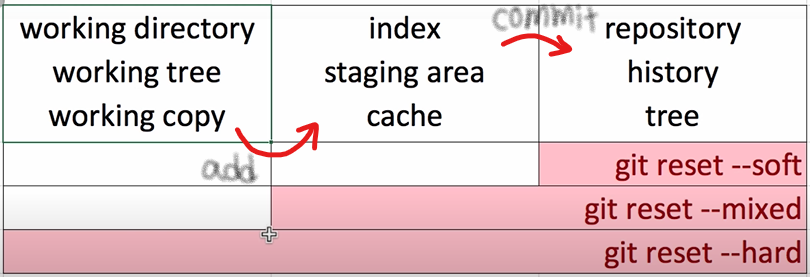 reset의 부과 효과에 따른 적용 범위, 보통 hard를 주로 사용
reset의 부과 효과에 따른 적용 범위, 보통 hard를 주로 사용
% 하지만 원격저장소를 통한 공유 repository에선 절대로 reset을 사용하면 안됨. (내장저장소에서만 사용하는 것을 권장)
% reset 취소하기! → 똑같이 reset을 이용해서 ORIG_HEAD로 복구하면 됨! (ORIG_HEAD 는 좀 신중한 일을 진행했을 때, 그 이전 commit에 대해 기록해 두는 것. 즉, 이전 상태를 정장해 둔 파일(commit 주소를 가리킴))
- revert :
reset과 같이 해당 commit의 이후 commit을 날려버리면서 돌아가는 것이 아닌, 해당 commit을 적용시킨 새로운 commit을 만들어 내는 것.
- commit을 취소하는 명령
- 버전에 따른 차이점, 과거의 임의의 시점의 내용을 확인할 수 있음
- TIP
- 모든 명령어에
--help를 붙이면 해당 명령어의 Document가 나옴. 이를 바탕으로 추가적인, 몰랐던 부분들을 알아가는 과정들이 필요.git commit -am ‘message’: -a 와 -m을 합쳐 사용. → add 없이 수정되거나 삭제,추가된 모든 파일을 commit하면서, editor를 사용하지 않고 해당 ‘message’를 통해 commit.git commit --amend -m ‘message’: 가장 최근의 commit 내용을 변경하는 방법. (local repo에서만 진행. 원격에 이미 올린 commit은 수정하지 않는 것이 좋음)
- 모든 명령어에
Git의 원리 (add, commit, status)
objects
- 데이터의 내용을 담고 있는 것
- 3가지로 구분됨.
- blob : 파일의 내용을 담고 있는 것
- tree : 파일들에 대한 정보들(파일 이름, 해당 파일의 내용이 가리키고 있는 objects 파일명(경로))을 담고 있는 것
- commit : 커밋에 대한 정보를 담고 있음 (tree, parent, …)
add의 원리(index, objects)
- git은 파일명이 달라도 같은 내용을 가지면 같은 object(파일명)를 가지게 됨.
- 파일이 100만개가 있더라도 이 모든 파일이 같은 내용을 가지고 있다면 단 1개의 object(파일명)만이 형성되어 있을 것.
- 즉, 내용을 기반으로 해서 파일의 이름(object)을 동일하게 설정함
→ sh1 Hash 알고리즘 사용!
→ 그래서 그 누구든지 간에 동일한 내용을 만든다면, 모든 사람들은 동일한 파일명(object)을 가지게 됨
→ 이를 바탕으로 add가 이루어지는 것! (내용에 따른 objects 파일명을 찾아 해당 파일명을 통해 내용을 표현해 줌)
commit의 원리
- commit을 하면 파일을 추가할 때 처럼 objects에 그 commit 내용이 저장되게 됨.
- 거기서 내용을 확인해 보면 tree, parent 라는 것이 존재 (이를 바탕으로 merge가 이루어지기도 함)
- tree : 그 commit이 일어난 시점에 존재하고 있는 모든 파일들에 대한 정보들(파일 이름, 해당 파일의 내용이 가리키고 있는 objects 파일명(경로))
- parent : 이전 commit이 누구인지를 지칭
- parent를 따라가면 결국 그 속에도 tree가 존재 → 이전 commit에 존재하고 있는 모든 파일들. 즉, 현 시점의 commit된 파일들이 아닌, 이전 시점의 commit된 파일들. (버전 관리 가능)
status의 원리
- status : 현재 상태에서 commit할 것이 있는지 없는지 (즉, 현dir에서 수정되거나 삭제되거나 추가된 파일이 있는지) 확인해 주는 역할.
- add 하기 전, 변경된 것들이 있는지 확인할 때. (즉, commit 대기 상태에 넣을 것이 있는지 판단하는 방법)
- index (staging area, add를 통해 반영된 사항들을 저장하고 있음)가 가리키고 있는 파일의 내용이 실제 파일의 내용(working directory의 파일, 내용 변경 후 add하지 않은 상태)과 다르다면 이를 인지하는 것.
- commit하는 시점에 어떤 파일이 변경되는지 인지하는 방법
- 이는 index의 내용과 가장 최근에 commit된 정보(중 tree의 내용)를 비교하여 판단해줌.
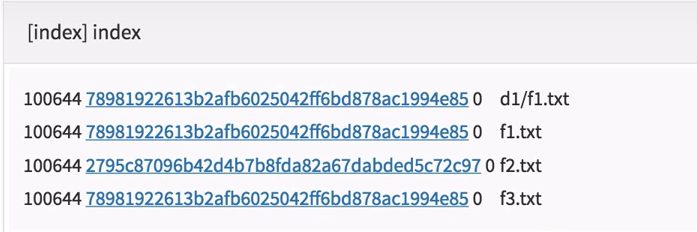
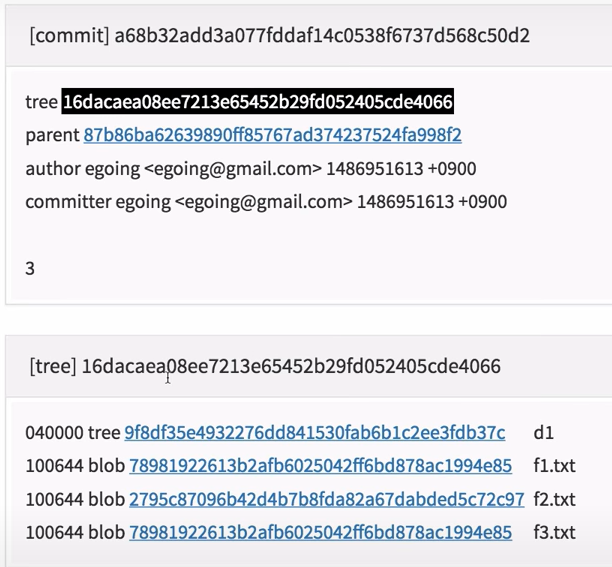
- 두개의 정보를 비교하여 변한 것이 있는지 인지하여 판단하는 것
- 비교는 결국 해당 sh1 hashcode 알고리즘을 통해 나온 값을 통해 이루어짐.
- 두개의 정보를 비교하여 변한 것이 있는지 인지하여 판단하는 것
- 이는 index의 내용과 가장 최근에 commit된 정보(중 tree의 내용)를 비교하여 판단해줌.
결론
- working directory ↔ index, staging area, cache ↔ repository
결론적으로 add는 working directory와 index(staging area)의 파일의 내용을 비교해서 add할 것이 있는 판단하고, commit은 index(staging area)와 repository의 파일의 내용을 비교해서 commit할게 있는지 판단.