순수 JPA 기반 Repository
- 스프링 데이터 JPA를 사용하지 않고, 순수한 JPA를 통해 기본 CRUD를 만든 다음, 이 CRUD들이 스프링 데이터 JPA에서는 어떻게 사용되는지 비교
사용 도메인
-
엔티티
-
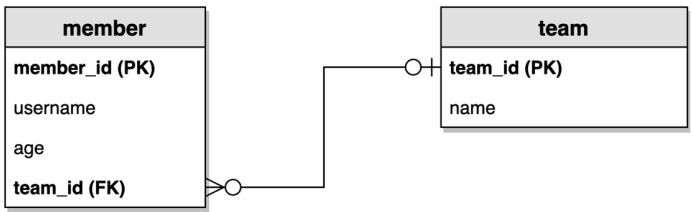
ERD(Entity Relationship Diagram)
-
연관관계 정의
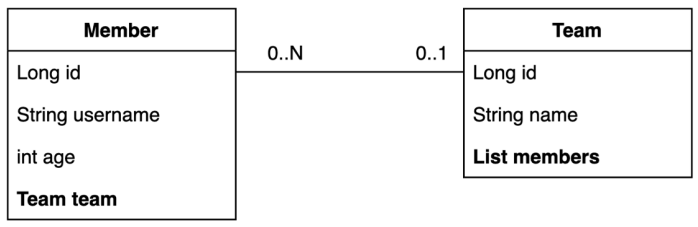
- Member ↔ Team
- 다대일↔일대다 양방향 관계
-
Member Entity
@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "team_id") private Team team;@ManyToOne(fetch = FetchType.LAZY): Team Entity와 다대일 관계를 표시, 지연로딩을 통해 Proxy객체가 설정될 수 있도록 세팅@JoinColumn(name = "team_id"): DB Table의 team_id col과 매핑하여 PK로 사용하겠다는 뜻. → 연관관계의 주인 설정
-
Team Entity
@OneToMany(mappedBy = "team") List<Member> members = new ArrayList<>();@OneToMany(mappedBy = "team"): Member Entity와 일대다 관계. 연관관계의 주인이 아니며 Member의 team에 의해 매핑된 field 라고 선언
- Member ↔ Team
기본 CRUD
-
필수 Dependency Injection
@PersistenceContext private EntityManager em; - 저장
- method :
save(Entity) - code :
em.persist(Entity);
- method :
- 삭제 :
- method :
delete(Entity) - code :
em.remove(Entity);
- method :
- 전체 조회 (JPQL)
- method :
findAll() - code :
em.createQuery("select e from Entity e", Entity.class).getResultList();
- method :
- 단건 조회
- method :
findById(Long id),find(Long id) - code :
em.find(Entity.class, id);
- method :
- 전체 개수 조회 (JPQL)
- method :
count() - code :
em.createQuery("select count(m) from Member m", Long.class).getSingleResult();
- method :
Spring Data JPA 사용하기 (공통 인터페이스 기능)
공통 인터페이스 설정
- Spring Data JPA 사용 전 설정
- Config 에서
@EnableJpaRepositories(basePackages = "...")와 같이 Annotation으로 Spring Data JPA 를 사용할 패키지 위치를 지정해주어야 했음 - 적용하게 되면 해당 패키지 및 하위 패키지에 적용
- 하지만, Spring Boot 에서는 자동으로 설정됨 → main Application 이 위치해 있는 패키지 및 하위 패키지에서 Spring Data Jpa를 사용할 수 있는 것
- Config 에서
- 공통 인터페이스 기능 사용하기
public interface MemberRepository extends JpaRepository<Member, Long> {}public interface TeamRepository extends JpaRepository<Team, Long> {}JpaRepository<Team, Long>Interface- 공통 CRUD 제공
- 제네릭 : <엔티티 타입, 식별자 타입>
public interface JpaRepository<T, ID extends Serializable> extends PagingAndSortingRepository<T, ID> {...}JpaRepository<Entity, PK Type>의 Entity 와 Pk Type 을 지정해주고 해당 인터페이스를 상속(extends) 받아 Repository Interface를 만들면 바로 Spring Data Jpa의 공통 인터페이스 기능 사용 가능!- 해당 인터페이스를 따로 구현하지 않아도 공통 인터페이스에서 제공하는 기등들을 사용할 수 있게 되는 것!
- Class단에
@Repository생략 가능- 컴포넌트 스캔을 스프링 데이터 JPA가 자동으로 처리
- JPA 예외를 스프링의 공통예외로 변환하는 과정도 자동으로 처리
-
원리
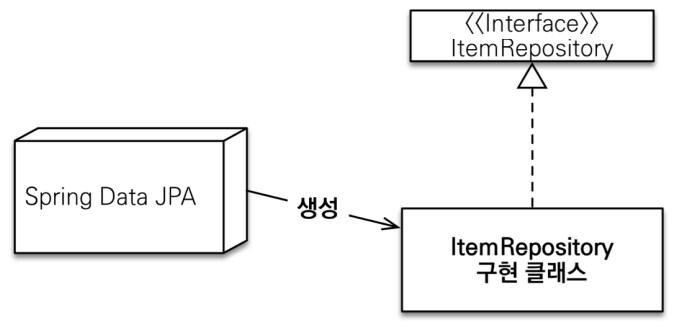
- 구현체가 없는데 어떻게 동작하지?
- Interface(
JpaRepository)와 Entity, Pk Type을 보고 Spring Data JPA가 구현 Class 를 자동으로 생성해주는 것! - 즉, 해당 interface 를 사용하는 시점에 Spring Data Jpa가 해당 Repo Interface가 JpaRepository를 extends 하고 있는 것을 확인하고 Entity, Pk Type을 통해 자기가 만든 구현체로 꽂아주는 것 (Proxy 기술을 통해)
공통 인터페이스 적용 (기본 CRUD)
- 이미 Spring Data Jpa가 구현해주었기 때문에 복잡하지 않은 기본 공통 인터페이스 기능에 한해서 따로 해줄 것 없이 사용만 하면 됨
- 필수 Dependency Injection → 없음! 이미
JpaRepository<Entity, Pk Type>에서 EntityManger를 DI 하고 있으므로! - 저장
memberRepository.save(Entity)code :em.persist(Entity);
- 삭제
memberRepository.delete(Entity)code :em.remove(Entity);
- 전체 조회
memberRepository.findAll()code :em.createQuery("select e from Entity e", Entity.class).getResultList();
- 단건 조회
memberRepository.findById(Long id),memberRepository.find(Long id)code :em.find(Entity.class, id);
- 전체 개수 조회
memberRepository.count()code :em.createQuery("select count(m) from Member m", Long.class).getSingleResult();
공통 인터페이스 분석
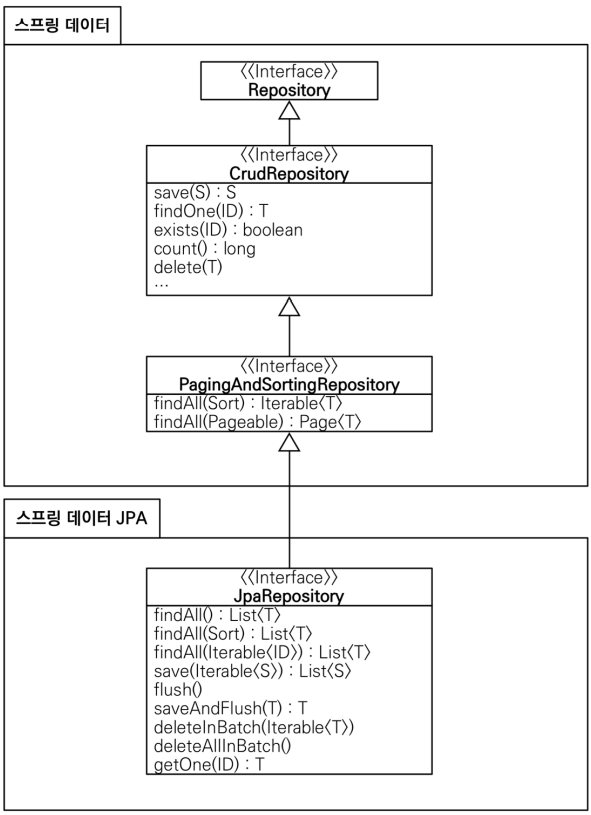
- 스프링 데이터 부분
- JPA만을 위한 부분이 아닌 공통 부분!
- 즉, Redis, NoSQL 등도 사용할 수 있는 interface라는 것
CrudRepository: 기본 공통 CRUD 기능 제공PagingAndSortingRepository: 페이지, 정렬 기능 제공
- 스프링 데이터 JPA
- JPA에 특화된 기술을 제공
- 아무리 공통화된 기술을 제공한다 해도 한계가 있기에, JPA에 특화되어 사용할 수 있는 기술 제공
스프링 데이터 JPA 분석
스프링 데이터 JPA 구현체 분석
org.springframework.data.jpa.repository.support.SimpleJpaRepository- 스프링 데이터 JPA가 제공하는 공통 인터페이스의 구현체
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> ... {
@Transactional
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
...
}
@Repository- 두가지 기능
- 컴포넌트 스캔 항목에 포함되어 스프링 빈으로 등록
- 해당 어노테이션이 달린 Class 에서 발생되는 Exception을 Spring에서 알아들을 수 있는 Exception으로 변경 (Repo에서 사용하는 것들은 JPA나 JDBC Template 등 서로 다른 하루 기술을 사용하는 일이 많은데 이 하부 기술이 변경되어도 Exception 처리는 동일하게 진행되는 이점을 얻음 → 하부 구현 기술을 바꾸어도 기존 비지니스 로직에 영향이 거의 미치지 않음)
- 이렇게 구현체에 이미
@Repository어노테이션이 달려있기 때문에, 우리가 사용하고자 하는 스프링 데이터 JPA Repository Interface에@Repository가 필요 없는 것
- 두가지 기능
@Transactional(readOnly = true)- 기본적으로 모든 Repo의 과정은 Transaction 단위로 이루어지게 끔 설정 (서비스 계층에서 트랜잭션을 시작하지 않으면 리파지토리에서 트랜잭션 시작, 서비스 계층에서 트랜잭션을 시작하면 리파지토리는 해당 트랜잭션을 전파 받아서 사용 )
- 기본값 :
readOnly = true→ 기본적으로 읽기전용으로 사용한다는 뜻 (스냅샷X(플러시 생략) → 성능 향상. 쓰기 전용은 각 메서드에@Transactional을 통해 세부적인(상세한) 설정으로 가져가줌) ⇒ 즉, Spring Data Jpa 를 사용하면 기본적으로 읽기전용이 알아서 실행됨 (쓰기모드가 필요한 애들은 알아서 쓰기모드로 설정됨) - But, 이건 기본 기능인 것(혹시 모르니 세팅해준 것). 즉 Transaction의 생명주기를 고려한다면 Service 단에서 Transaction을 시작해주고 Repo에 들어오는 것이 좋음!
스프링 데이터 JPA 구현체의 save 메서드 분석
@Transactional
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
save- 새로운 Entity →
persist - 새로운 Entity X →
merge- 해당 Entity를 DB에서 가져와 현재 내용으로 바꿔치기(덮어쓰기)함
- 데이터 변경을 merge로 하는 경우가 있는데, 데이터 변경은 변경감지를 통해 이루어져야함
- merge는 영속상태에서 벗어난 Entity를 다시 영속상태로 만들어줘야 할때 사용
- 새로운 Entity →
- 새로운 Entity를 판단하는 기본 전략
- 식별자가 객체(String, Long, … )일 때
null로 판별될 때 - 식별자가 자바 기본 타입(long, int, … )일 때
0으로 판별될 때
- 식별자가 객체(String, Long, … )일 때
- 만약
@GeneratedValue를 사용하지 않고 직접 ID를 부여한다면?- 기본 로직에 따르면 직접 부여하게 되면 새로운 Entity로 판단되지 않아 persist 가 아닌 merge 가 동작하게 됨
- 이때 필요한 것이
Persistable<ID>Interface Persistable<ID>- 새로운 엔티티 확인 여부를 직접 구현할 수 있게하는 Interface
// extends Persistable<ID> @Id private String id; @CreatedDate private LocalDateTime createdDate; @Override public String getId() { return id; } @Override public boolean isNew() { return createdDate == null; }PersistableInterface의isNew()를 구현하여 완성 → 새로운 Entity인지 아닌지에 대한 판별을 직접 구현하는 것- 이때
isNew()에는@CreatedDate를 사용한 Field를 통해 판별하는 것이 좋음@CreatedDate는 persist 직전에 해당 Entity가 저장된 시각을 기록함.null: persist 되지 않은 새로운 Entity.nullX : persist가 되었던 Entity