영속성 관리 이해 - 기본
엔티티 매니저 팩토리와 엔티티 매니저
-
동작 원리
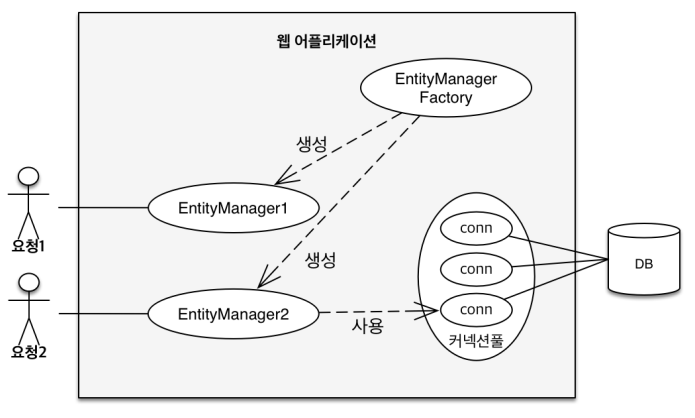
- 사용자의 요청이 들어오면 EntityMangerFactory 에서 EntityManger를 생성하고
- EntityManger는 내부적으로 DB를 사용하게 됨
영속성 컨텍스트
- 개념
- JPA를 이해하는데 가장 중요한 용어
- 엔티티를 영구 저장하는 환경 (논리적인 개념, 눈에 보이지 않음)
- 엔티티 매니저를 통해 접근 가능
- 영속성 컨텍스트로써의
em.persist(entity): DB에 객체를 저장하라? X ⇒ 영속성 컨텍스트에 객체를 저장하라 O
- 엔티티의 생명주기
- 비영속
- 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
- 즉, 객체를 그냥 생성만 한 상태 (
em.persist(…)를 하지 않은 객체)
- 영속
- 영속성 컨텍스트에 관리되는 상태
- 객체를 생성하여 영속성 컨텍스트에 넣은 상태 (
em.persist(…)를 통해 객체를 영속성 컨텍스트에 담은 것) - 해당 객체는 트랜섹션(Transaction)이라는 하나의 단위에서 영속성 컨텍스트에 의해 관리됨
- [주의] 영속성 컨테스트에 담긴다고 바로 query가 나가는 것은 아님 → Transaction이 commit 되는 시점[
tx.commit()]에 DB에 query가 나감!
- 준영속
- 영속성 컨텍스트에 저장되었다가 분리된 상태
em.detach(…): 영속성 컨텍스트에서 해당 객체를 지움
- 삭제
- 객체가 삭제된 상태
- 비영속
- 영속성 컨텍스트의 이점
- 1차 캐시
- 영속성 컨텍스트로 생각하면 됨
em.persist()하는 순간 1차 캐시에 저장됨- map으로 되어 있음 (key:
@Id로 설정한 값(식별자), value : Entity) - 이런 방식을 사용하면 조회에서 이점 발생
- 조회 시 DB에서 먼저 해당 Entity를 가져오는 것이 아니라, 1차 캐시에 존재한지 확인 후 있으면 해당 Entity를 반환해주고, 없다면 DB에서 가져옴
-
1차 캐시에 해당 Entity가 존재한 경우 (1차 캐시에서 조회)
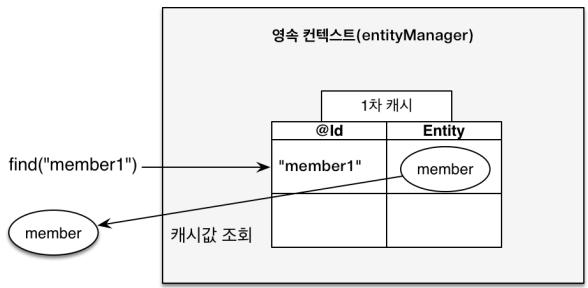
-
1차 캐시에 해당 Entity가 존재하지 않는 경우 (DB에서 조회)
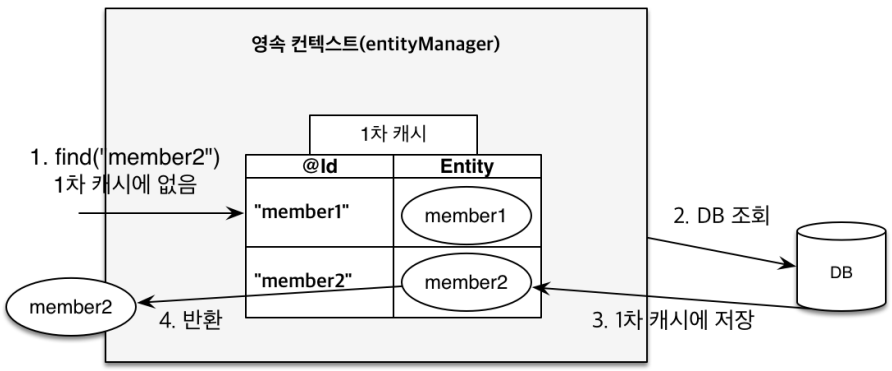
-
- [참고] 2차 캐시 : Application 전체에서 공유하는 캐시. 1차 캐시는 Transaction 하나에서 존재
- 해당 기능은 성능적인 측면에서 우월한 이득을 준다기 보다는 컨셉적인 측면에서 이득을 줌 (객체 지향적인 설계를 위함)
-
Entity 조회 시 동일성 보장
Member member1 = em.find(Member.class, 1L); Member member2 = em.find(Member.class, 1L); System.out.println(member1 == member2); // true- 한번 조회한 후로는 영속성 컨텍스트의 똑같은 객체(주소) 를 가져오기 때문에 당연히 동일성 보장
- 마치 Java Collection에서 조회하는 듯한 느낌을 줌
- Entity 등록 시 “트랜잭션을 지원하는 쓰기 지연” 가능
em.persist(member1); em.persist(member2);매 순간마다 INSERT query가 나가는 것이 아닌, Transaction을 커밋하는 순간에 DB에 INSERT query를 한번에 보냄- “쓰기 지연 SQL 저장소”가 존재하기에 가능한 것.
-
em.persist(member1);순간, 영속성 컨텍스트에 해당 Entity를 넣음과 동시에 해당 INSERT query를 SQL저장소에 쌓아둠 (em.persist(member2);도 마찬가지)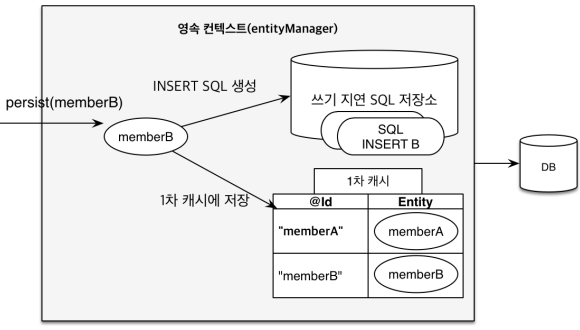
-
Transaction이 commit 하는 순간(
tx.commit()) 쌓아뒀던 SQL query들을 DB로 보냄(flush()). → 이때 DB에 반영이 되는 것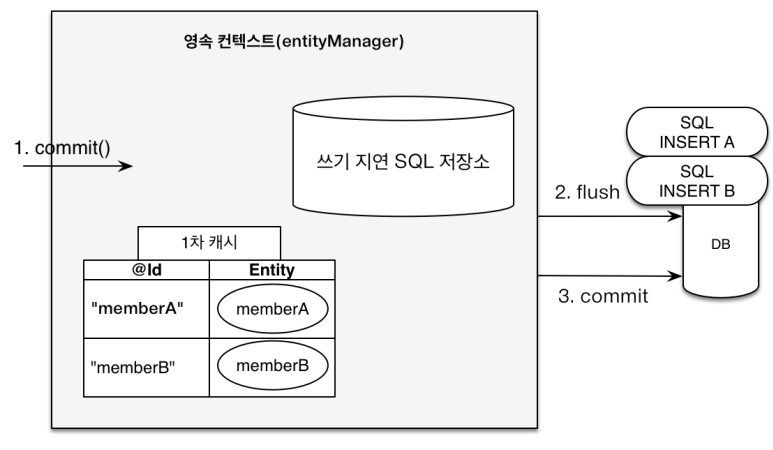
- SQL 저장소를 이용해서 한방에 query를 날리는 이유는 “최적화”를 위함 → 버퍼링 (최적화의 여지를 주는 것!), JDBC Batch 기능 (
<property name="hibernate.jdbc.batch_size" value="10" />한방에 10개를 모아서 query를 보내는 것)
-
Entity 수정 시 변경감지(Dirty Checking)
Member member = em.find(Member.class, 1L); member.setName("Edited") // em.update() 가 필요없나???- 이렇게 영속성 컨텍스트로 해당 Entity를 가져온 후
- Entity를 수정만 해주면 직접 update할 필요없이 EntityManger가 알아서 commit 시점에 UPDATE query를 날려줌 (변경 감지)
- Java Collection에서의 객체 수정이라 생각하면 됨 (Collection의 요소 객체를 수정하고 다시 해당 객체를 Collection에 넣지 않는다는 점 중요)
-
동작 원리
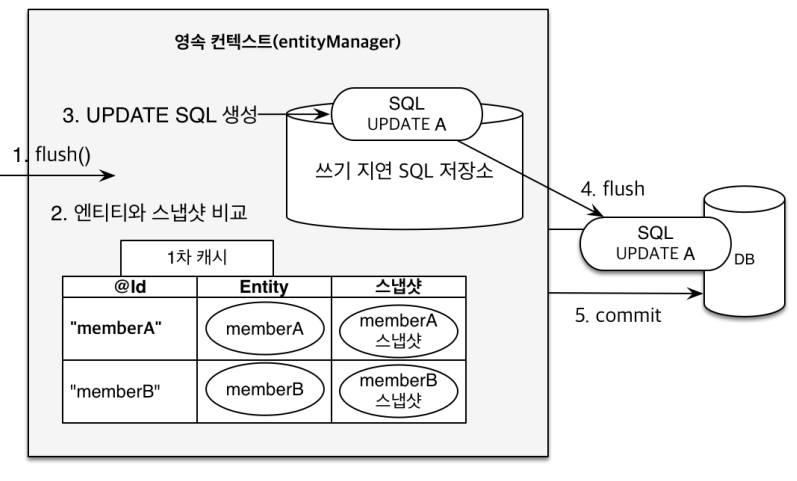
- JPA는 커밋 시점에 Entity와 스냅샷 비교 (스냅샷 : 처음 Entity를 영속성 컨텍스트로 가져올 때의 Entity 상태. 즉, 최초 시점의 Entity)
- 비교했을 때 달라진 점에 대해서 UPDATE query를 생성하여 SQL 저장소에 저장
- [중요] 이런 기능들 때문에 당연히 모든 데이터 변경은 Transaction 단위 내에서 진행되어야 함!!!
- 1차 캐시
영속성 관리 이해 - 심화
플러시
- 영속성 컨텍스트가 변경내용을 데이터베이스에 반영
- 영속성 컨텍스트의 변경사항과 데이터베이스를 맞추는 작업
- 보통 Transaction 이 commit 될 때 flush가 일어남 (혹은
em.flush()로 플러시 강제 실행 가능) - [주의] 플러시한다고 1차 캐시가 지워지는 것은 아님 (강제 영속성컨텍스트 비움 :
em.clear()) - 플러시 발생 시
- 변경 감지 (스냅샷과의 비교를 통해)
- 수정된 Entity 를 “쓰기 지연 SQL 저장소”에 등록
- 최종 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송 [등록, 수정, 삭제 query. not 조회 query]
- 플러시 방법
- 직접 호출 :
em.flush() - 자동 호출 : Transaction commit (
tx.commit()) - 자동 호출 : JPQL 쿼리 실행
- JPQL은 “쓰기 지연 SQL 저장소”와 독립적으로 실행됨. (SQL 그 자체로 실행)
- JPQL은 영속성 컨텍스트를 거치지 않고 바로 DB로 SQL 자체가 실행(query를 보내는)되는 것이기 때문에 DB에 이전의 데이터들의 변경이 반영되지 않으면 원치 않은 결과를 얻을 수 있음.
- 그러기에 JPQL이 실행되기 전에 자동으로 플러시가 호출됨 → 현재까지 변경된 부분을 반영해주기 위해 (영속성 컨텍스트와 DB의 싱크를 맞추기 위함)
-
ex)
em.persist(memberA); // DB query가 나가지 않은 상태. (영속성 컨텍트스에 저장) em.persist(memberB); // DB query가 나가지 않은 상태. (영속성 컨텍트스에 저장) List<Member> members = em.createQuery("select m from Member m", Member.class)getResultList(); // DB에서 저장된 Member들을 가져오는 것에서 만약 JPQL이 발동할때 자동으로 Flush가 호출되지 않는다면, JPQL 결과는 빈 List가 됨. 이런 것들을 방지하기 위해서 JPQL이 실행되기 전 Flush를 실행해주어 DB에 데이터 변경을 반영하고 그 결과를 가져와 주는 것
- 직접 호출 :
준영속 상태
- 영속 상태의 엔티티가 연속성 컨텍스트에서 분리(detached)
- 영속성 컨텍스트가 제공하는 기능(변경 감지, … )을 사용하지 못함
- 준영속 상태로 만드는 방법
em.detach(Entity): 지정된 엔티티를 준용속 상태로 전환 (일부)em.clear(): 영속성 컨텍스트를 완전히 초기화. 영속성 컨텍스트의 1차 캐시를 통째로 비우는 것 (전체)em.close(): 영속성 컨텍스트를 종료 (전체)