JPA는 왜 필요한가?
객체지향언어와 SQL(관계형 DB)
- 관계
- 현재 시대는 객체를 관계형DB에 관리하는 시대
- 객체지향언어과 SQL을 동시에 사용
- 문제점
- 객체지향언어를 사용하면서 코드 자체는 객체지향적으로 사용하지 않고 SQL에 집중하여 SQL 중심적으로 코드를 짬!
SQL 중심적인 개발의 문제점
- 문제점
- SQL을 통해 CRUD 를 하기 위해 직접 해당 query를 작성
- 또한, 자바 객체를 SQL로.. SQL을 자바 객체로.. 변환하며 복잡하고 번잡한 코드를 작성
- ex) 객체 필드 추가에 따른 CRUD 변경 (매핑을 위한 작업을 일일히 수정해주어야 함!)
- 그렇다고 SQL에 의존적인 개발을 피하기는 사실상 불가능
- 패러다임의 불일치
- 객체지향의 사상 vs 관계형 DB의 사상
- 관계형 DB의 사상 : 데이터를 잘 보관하여 정규화하는 것이 목표
- 객체 지향의 사상 : 속성과 method를 잘 묶어 캡슐화하는 것이 목표
- 즉, 둘의 패러다임(사상)이 달라서 여러가지 문제점이 발생
- 결국 이 패러다임의 불일치를 해결하기 위해 객체 ↔ SQL 매핑 작업이 필수적이며 이는 개발자가 진행함에 있어서 주 비지니스를 맡기 보다는 SQL 매퍼가 되어가는 상황을 직면 (해결이 시급했음!)
- 객체와 관계형 DB의 차이
-
상속 (객체 O RDB X) - RDB에서 객체의 상속 관계와 가장 유사한 것이 ‘슈퍼타입 서브타입 관계(DTYPE)’
- 하지만 이를 객체와 매핑하려면 저장, 조회 등에서 굉장히 복잡하며 비효율적인 과정을 거쳐야 함
- 그렇다면 DB가 아닌 Java Collection에 저장한다 생각하면? → 저장, 조회가 굉장히 쉬워짐. 또한 다형성 활용도 가능!
-
연관관계 (객체 : 참조 RDB: PK, FK, Join) - ❗ 객체는 추가설정이 없는 한 단방향으로 밖에 이동 불가능, RDB는 추가설정 없이 양방향 이동 가능
- 패러다임의 차이를 해결하기 위해 만약 객체를 테이블에 맞추어 모델링한다면? → 말 그대로 객체 지향적인 코드가 아님!
- SQL의 JOIN 을 통해서 객체를 가져올 경우 객체 그래프 탐색이 불가능 → 처음 query를 통해 불러온 범위에 의해서 한정됨. → 그에 따른 엔티티 신뢰 문제(객체의 연관관계를 신뢰하며 그냥 부를 수 없게 되는 것! query에서 불러오지 않았을 수도 있으므로) 발생!! (물리적으론 가능하지만, 논리적으로는 불가능한 경우)
- 그렇다고 모든 객체를 미리 로딩할 수는 없음
- 만약 DB가 아닌 Java Collection에 저장한다 생각하면? → 참조값이 함께 들어가기 때문에 저장 및 조회가 간단해지고 객체 그래프 탐색 가능!
- 데이터 타입, 데이터 식별 방법 등
-
- 즉, RDB에 객체를 저장하며 객체답게 모델링 할수록 매핑 작업만 늘어나며 비효율적인 상황이 발생하게 됨!
- 그렇다면 지속적으로 봐왔던 것처럼 객체를 Java Collection에 저장하듯이 DB에 저장할 수는 없을까?? → JPA(Java Persistence API) 개념 도입
JPA(Java Persistence API)
JPA
- Java Persistence API
- 인터페이스의 모음 (즉, 구현체를 요구함 → 구현체는 대표적으로 Hibernate 를 사용)
- “DB 이용을 마치 Java Collection에 객체를 담는 식으로 이용한다”는 사상
- 자바 진영의 ORM 기술 표준 ⇒ ORM(Object-relational mapping = 객체 관계 매핑) : 객체는 객체대로 설계하고 관계형 DB는 관계형 DB대로 설계한 후 해당 프레임워크가 중간에 알아서 매핑해준다는 의미
-
JPA는 Application과 JDBC 사이에서 동작!
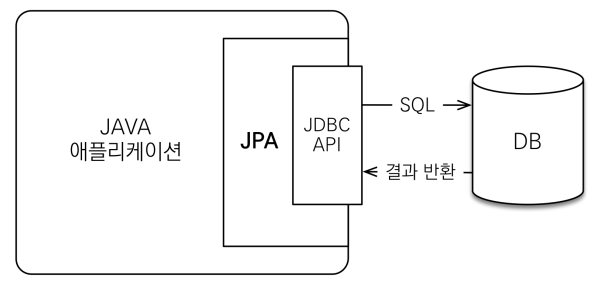
- 개발자가 직접 JDBC를 사용하는 것이 아니라
- 개발자가 JPA에게 명령을 내리면 JPA가 JDBC API를 사용하여 DB에 접근하는 것
- JPA 동작
-
저장
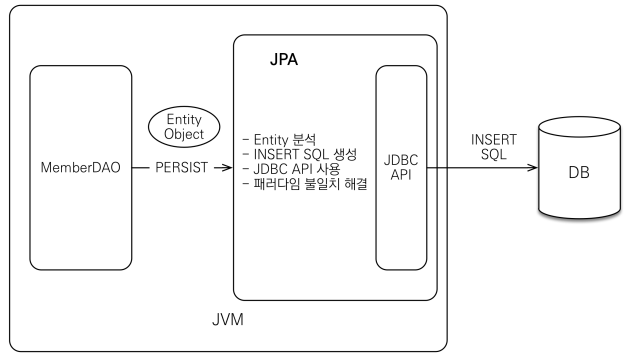
- JPA에게 Entity 객체와 명령어를 같이 보내주면
- JPA는 Entity를 분석하여 그에 맞는 INSERT query를 생성하여 JDBC API를 이용하여 DB를 사용하게 됨
- JPA가 자동으로 직접 query를 생성해준다는 부분이 중요!
- 패러다임 불일치 해결!
-
조회
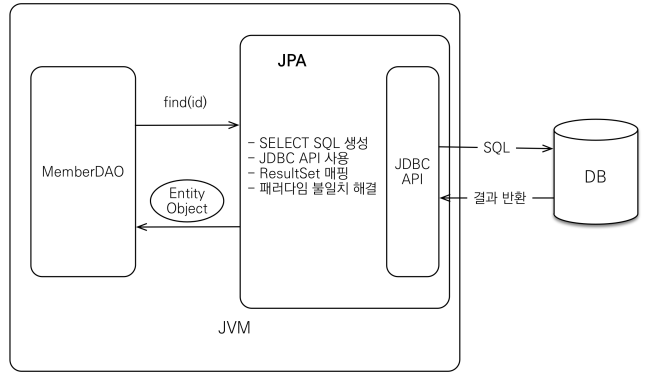
- JPA에게 해당 Entity 객체를 찾으라 명령하면
- JPA는 Entity를 분석하여 적절한 SELECT query 를 만들어 JDBC API를 이용하여 DB에 접근
- 그 후 해당 ResultSet을 객체에 자동으로 매핑해줌
- 패러다임 불일치 해결!
-
즉, JPA가 그 번잡했던 작업들(CRUD, 매핑, … )을 직접해준다는 것!!
-
JPA는 왜 사용해야 하는가?
- 생산성 (JPA와 CRUD)
- 저장 :
em.persist(member) - 조회 :
em.find(memberId, Member.class) - 수정 :
member.setName(”변경 이름”)→ 영속성 컨텍스트 속 변경감지 - 삭제 :
em.remove(member) - 이와 같이 JPA가 제공하는 것을 통해 CRUD를 쉽게 이용할 수 있음
- 저장 :
- 유지보수
- 기존 : 객체 필드 변경 시, Table에 매핑하기 위해 모든 CRUD query를 수정해야 했었음
- JPA 사용 : 자동으로 매핑되기에 알아서 적용됨. 즉, CRUD query는 JPA가 처리해줌
- JPA와 패러다임의 불일치 해결
- 상속 관계
- JPA를 통해 상속 관계에 있는 객체를 저장 및 조회해주면 해당 관계의 모든 객체를 알아서 저장 및 조회해줌 → 즉, DB 중심적인 개발에서 벗어날 수 있음
- 연관 관계
- 저장 : 연관관계에 있는 객체 하나를 저장하면 해당 객체와 연관된 객체를 알아서 저장해줌 (cascade)
- 조회 : 한 객체를 조회하면, 그와 연관관계가 있는 객체를 알아서 끌어와줌 (fetch) → 객체 그래프 탐색 가능
- 마치 Java Collection 에서 객체를 다루듯이 DB를 이용할 수 있어짐
- 신뢰할 수 있는 Entity, 계층
- JPA의 “지연 로딩, 즉시 로딩”에 의해 가능한 부분
- JPA를 통해서 연관관계 저장 및 접근이 확실히 이루어진다는 것을 알 수 있음
- 그에 따라 자유롭게 객체 그래프 탐색이 가능해짐
- 객체 비교
- 동일한 Transaction에서 조회한 Entity는 같음을 보장 (식별자 사용)
- 상속 관계
- JPA의 성능 최적화 기능
- 1차 캐시와 동일성 보장
- 동일한 Transaction안에서는 같은 Entity를 반환 (즉, 캐시를 사용) → 약간의 조회 성능 향상
- Transaction을 지원하는 쓰기(INSERT) 지연
- Transaction 커밋할 때까지 INSERT query를 모음
- JDBC BATCH SQL 기능을 사용하여 한번에 SQL 전송 (JPA를 통해 쉽게 이용할 수 있어진 것)
- 즉, 그 즉시 query가 나가는 것이 아닌, 일단 모은 후에 중복되는 것들에 대해선 최적화 시켜준 후 한번에 query를 보내어 성능 최적화 실시 → 네트워크 측면에서의 최적화
- 즉시 로딩과 지연 로딩
- 지연 로딩 : 일단 객체를 모두 끌어와 놓는 것이 아닌, 실제 필요할 때에 끌어 오는 것 → Proxy 기능 사용
- 장점 : 쓸데없는 데이터를 불러오지 않아도 됨. 무한루프에 빠질 염려가 없음 (연관관계 속 무한루프)
- 단점 : query가 많이 나감 (네트워크 측면)
- 즉시 로딩 : 불러오는 객체와 연관된 모든 객체를 미리 끌어와 놓아 사용하는 것
- 장점 : query 한방으로 해결
- 단점 : 쓸데없는 데이터를 모두 가져오게 되어 부담이 되고, 무한 루프에 빠질 위험이 존재
- 지연 로딩 : 일단 객체를 모두 끌어와 놓는 것이 아닌, 실제 필요할 때에 끌어 오는 것 → Proxy 기능 사용
- 1차 캐시와 동일성 보장
JPA 프로젝트 기본 설정
프로젝트 생성
- Maven
- Java 라이브러리, 빌드 관리
- 라이브러리 자동 다운로드 및 의존성(Depedency) 관리
- 요즘은 Gradle을 더 많이 사용
- 이전 자료들은 보통 Maven을 기준으로 사용하기 때문에 알아두면 좋음
프로젝트 설정
- 라이브러리 설정 (JPA, DataBase 라이브러리)
-
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>jpa-basic</groupId> <artifactId>ex1-hello-jpa</artifactId> <version>1.0.0</version> <dependencies> <!-- JAVA11에서 Hibernate를 사용하기 위함 --> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.0</version> </dependency> <!-- JPA 하이버네이트 --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>5.3.10.Final</version> </dependency> <!-- H2 데이터베이스 --> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <version>1.4.199</version> </dependency> </dependencies> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> </properties> </project> - JPA Hibernate 라이브러리 다운로드 및 의존성 추가
- H2 DataBase 라이브러리 다운로드 및 의존성 추가
- Java 11 에서 Hibernate 를 이용하기 위한 라이브러리 다운로드 및 의존성 추가
-
- JPA 설정
-
persistence.xml
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.2" xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"> <persistence-unit name="hello"> <properties> <!-- 필수 속성 --> <property name="javax.persistence.jdbc.driver" value="org.h2.Driver"/> <property name="javax.persistence.jdbc.user" value="park"/> <property name="javax.persistence.jdbc.password" value=""/> <property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/jpa-basic"/> <property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/> <!-- 옵션 --> <property name="hibernate.show_sql" value="true"/> <property name="hibernate.format_sql" value="true"/> <property name="hibernate.use_sql_comments" value="true"/> <property name="hibernate.hbm2ddl.auto" value="create" /> </properties> </persistence-unit> </persistence>- JPA 설정 파일
- 정해진 규칙에 따라 “/META-INF/persistence.xml” 에 위치
- javax.persistence로 시작하는 속성: JPA 표준 속성
- hibernate로 시작하는 속성: 하이버네이트 전용 속성
-
JPA는 특정 DB에 종속하지 않기에 여러 각각의 DB의 문법,함수 차이에 영향을 받지 않음 (데이터베이스 방언)
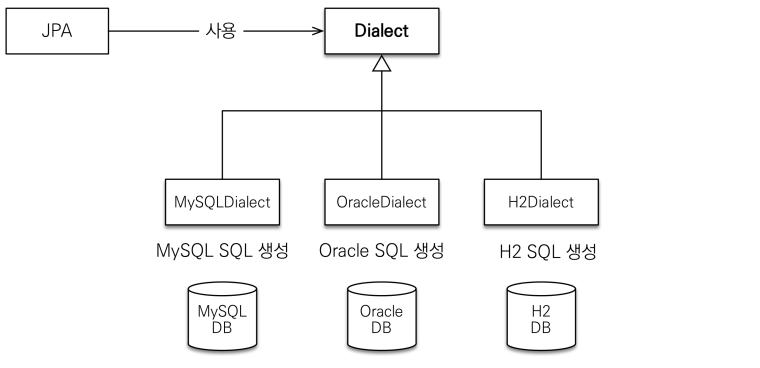
- 속성 파일의
<property name="hibernate.dialect" value="..."/>부분 - Hibernate는 40가지 이상의 DataBase Dialect 지원
- 속성 파일의
-
JPA 기본 사용법
JPA 구동 방식 이해
-
JPA 구동 방식
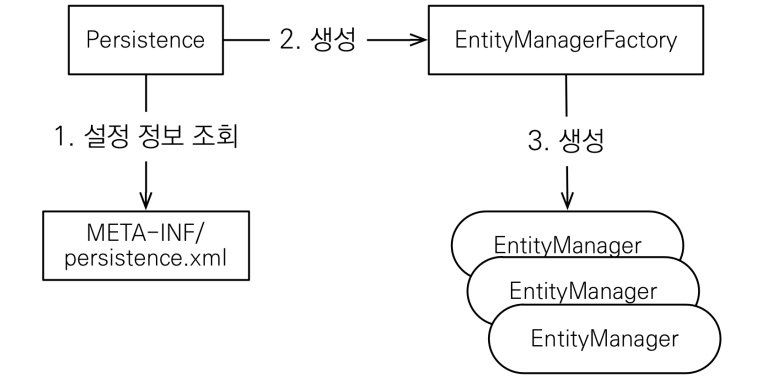
- 먼저 persistence.xml 에 설정된 JPA 설정 정보를 이용한 Persistence를 통해 EntityMangerFactory 생성 →
EntityManagerFactory emf = Persistence.*createEntityManagerFactory*("hello");- EntityMangerFactory
- EntityManger 를 여러 개를 관리하고 생성할 수 있는 Factory.
- application 에서 하나만 생성해서 사용해야 됨
- 모든 application 의 동작이 끝나면 닫아줘야 함 →
emf.close();
- EntityMangerFactory
- 그 후 EntityMangerFactory를 통해 EntityManger 생성 →
EntityManager em = emf.createEntityManager();- EntityManger
- DB 조회, 저장 등 단일적인 DB 연결 및 사용 시 Entity Manger 를 생성하고 이를 통해 진행
- 쉽게 생각하면 DB Connection 을 하나 받았다고 생각
- 여러개 생성 가능
- 고객의 요청이 올 때마다 생성하고 버려지고 하는 존재 (그냥 진짜 DB Connection 과 같다 생각하면 됨)
- 엔티티 매니저는 쓰레드간에 공유해선 안됨 (사용하고 버려야 함)
- 한 단위의 작업이 끝나면 항상 엔티티 매니저는 닫아줘야 함 →
em.close();
- EntityManger
- 실제 DB와의 작업을 위해 Trasaction 생성 →
EntityTransaction tx = em.getTransaction();- Transaction
- 저장, 조회, 삭제, 수정 등 모든 EntityManger의 작업이 이루어지는 하나의 단위
- 모든 EntityManger의 작업(데이터 변경)은 해당 Transaction 안에서 이루어져야 됨
- Transaction 시작 :
tx.begin(); - Transaction 끝 및 SQL 쿼리저장소 속 query 전송 :
tx.commit();→ commit 으로 최종 query 를 날리는 것 - [참고] Transaction 작업 취소 :
tx.rollback();
- Transaction
- 먼저 persistence.xml 에 설정된 JPA 설정 정보를 이용한 Persistence를 통해 EntityMangerFactory 생성 →
JPA 사용
- 객체와 테이블 생성 및 매핑
@Entity- 해당 Class 를 Entity 로 사용하겠다! 선언하는 것 → 원하는 객체를 Table과 매핑시키겠다는 것
- 즉, Entity Manger 에서 관리하겠다는 뜻
@Id- 해당 Field 를 PK(Primary Key) 로 설정
- 필수 값 → 영속성 컨텍스트(1차 캐시)에서 해당 id 값을 key 로 사용하고 Entity 를 value 로 사용하여 저장하기 때문
- ex) Member 객체 생성 및 Table과 매핑
-
Member 객체
@Entity public class Member { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; //Getter, Setter … } -
그에 따른 Member Table (JPA가 자동으로 생성해준 Create query)
create table Member ( id bigint not null, name varchar(255), primary key (id) );
-
- JPA를 통한 객체 Baisc CRUD
-
객체
Member member = new Member(); member.setId(1L); member.setName("HelloA"); // 비영속 상태 - 객체 저장 :
em.persist(member) - 객체 조회 :
Member foundMember = em.find(Member.class, member.getId()); - 객체 수정 :
foundMember.setName("Edit Hello");[변경 감지] - 객체 삭제 :
em.remove(foundMember); - JPA를 통해서 ORM을 실행한다면, 이전과는 다르게 굉장히 간단하게 DB CRUD가 가능 해지며, 번잡한 매핑과정도 거치지 않아도 됨!
-
JPQL 간단 소개
- SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어
- 테이블이 아닌 객체를 대상으로 검색하는 객체 지향 쿼리 → SQL을 추상화해서 특정 데이터베이스 SQL에 의존X
- SQL과 문법 유사, SELECT, FROM, WHERE, GROUP BY, HAVING, JOIN 지원
- JPA의 가장 단순한 조회방법으로는 비지니스로직을 수행할 수 없는 경우 사용 [ ex) 나이가 10세 이하인 회원 모두를 조회 ]
- 검색을 할 때도 테이블이 아닌 Entity 객체를 대상으로 검색 가능
- 즉, JPA의 기본 조회에서 검색 조건이 포함된 SQL을 추가한 것