API 개발 고급 (Part 2, 주문 조회 API)
- 목표: 컬렉션 조회 최적화! (xToMany)
- 주문 조회 API (Collection 조회)
- 주문 + 배송정보 + 회원을 조회하는 API
- RestAPI 사용 → @RestController = @Component(Spring Bean으로 등록) + @Responsebody(JSON 이나 XML로 데이터를 바로 보내는 용도)
- 지연 로딩에 의한 성능저하를 해결하는 방향으로.
- xToOne (FetchType.LAZY) 과 관련된 조회 성능을 올리는 방법
- 즉, Order에서 Member와 Delivery 정보까지 받아오기
- Part 1 (xToOne)
- Order ↔ Member : ManyToOne
- Order ↔ Delivery : OneToOne
- Part 2(xToMany, Collection 조회)
- Order ↔ OrderItems : OneToMany
- Part 1 (xToOne)
[Version 1] Entity를 직접 노출하여 반환
@GetMapping("/api/v1/orders")- Entity를 직접 노출하여 반환 :
public List<Order> orderV1() -
이제 Order에 있는 OrderItems collection을 조회해야 됨
List<OrderItem> orderItems = order.getOrderItems(); orderItems.stream().forEach(oi -> oi.getItem().getName());- 먼저 order.getOrderItems를 통해 내가 받아온 Order의 orderItem collection에 접근해줌
- 근데 이때의 해당 collection의 각 orderItem은 프록시 상태 (Lazy이기 때문!)
- 이 프록시 상태를 벗어나게 하기 위해 각 orderItem에서 getItem으로 실제 Entity를 가져올 수 있도록 Lazy 강제 초기화
- 이때 getItem을 했는데, 이 Item 또한 Lazy이기 때문에 프록시 상태. 즉, Item도 getName을 통해 실제 Entity를 가져올 수 있도록 Lazy 강제 초기화 실시
- 각 Entity의 상태 변화
- order : query를 통해 직접 조회 → 처음부터 실제 Entity
- member : order와 ManyToOne 관계이며 Lazy로 인한 프록시 상태. → getName() 을 통해 Lazy 강제 초기화
- delivery : order와 OneToOne 관계이며, Lazy로 인한 프록시 상태 → getAddress()를 통해 Lazy 강제 초기화
- orderItem : order와 OneToMany 관계, collection으로 모여져 있는 상태이며 각 orderItem은 Lazy로 인한 프록시 상태, → getItem을 통해 Lazy 강제 초기화 (한방 쿼리로 나감 → 컬렉션이니깐)
- Item : orderItem과 연관, ManyToOne 관계. Lazy로 인한 프록시 상태 → getName()을 통해 Lazy 강제 초기화
- !! 여기서도 양방향 관계에 대해선 한 곳에 @JsonIgnore를 달아줘야 함 !!
- 당연히 Entity를 직접 노출하여 반환하게 하는 것은 안됨! → DTO로 변환 필요 (Ver2)
[Version 2] Entity로 조회하여 DTO로 변환하여 데이터 반환
@GetMapping("/api/v2/orders")- DTO로 변환하여 반환 →
List<OrderDto> orderV2() - DTO
- DTO로 내보낼거면 DTO 안에 있는 요소들도 Entity에 대한 의존도를 아예 없애야 됨. 즉, 모든 것들을 DTO로 만들어야 된다는 것
- 지금 DTO로 변환해서 반환해야 될 항목은 먼저 Order이지만, Order 안의 collection으로 존재하고 있는 OrderItem 또한 DTO로 변환해주어야 함!
- OrderDto
- 다른 부분(member, delivery, ..)들은 Chapter2와 동일
-
orderItem을 저장하는 Collection 부분이 중요! → 해당 collection 안에 들어가는 orderItem은 Entity가 아닌 DTO여야 함! →
List<OrderItemDto> orderItem;@Data static class OrderDto { ... private List<OrderItemDto> orderItem; public OrderDto(Order o) { ... o.getOrderItems().stream().forEach(oi -> oi.getItem().getName()); // Lazy 강제 초기화 orderItem = o.getOrderItems().stream() .map(oi -> new OrderItemDto(oi)).collect(Collectors.toList()); // 각 orderItem을 DTO로 변환 } }- order의 orderitems collection의 각 orderitem 및 orderitem의 Item의 프록시 상태 벗어나게 하기 (Lazy 강제 초기화)
- order의 orderitems collection의 각 orderitem이 프록시 상태를 벗어낫기에, 이제 각 orderItem을 DTO로 변환해서 반환해주기.
- OrderItemDto
-
orderItem을 DTO로 변환
@Data static class OrderItemDto { // API에서 요구하는 스펙 (가정) private String itemName; // 상품 명 private int orderPrice; // 주문 가격 private int count; // 주문 수량 // DTO는 Entity를 인자로 받아도 됨! public OrderItemDto(OrderItem oi) { itemName = oi.getItem().getName(); // 애는 Item Entity 가 들어가는 게 아니라 item의 이름 (String)이 들어간느 것임! // 그래서 Item DTO는 따로 만들 필요가 없음. OrderItem의 해당 정보를 넣기에 orderPrice = oi.getOrderPrice(); count = oi.getCount(); } }- API에서 요구하는 스펙에 해당하는 변수들만을 저장한다고 가정 (즉, Item Entity를 반환해주는 것은 아님 → so, Item DTO를 따로 만들 필요 없음.)
- 이런 식으로 진행하면 당연히 1 + N 문제가 발생! 근데 또 그 N에서도 1+N 문제가 발생하게 됨! (Order의 collection 조회이니깐!)
- DTO로 변환하여 반환하기는 했지만, 이는 너무나 많은 query가 나감. So, 성능 최적화 필요! → Fecth Join, Distinct 사용 (Ver3)
[Version 3] Fecth Join, Distinct를 통한 성능 최적화 (DTO)
@GetMapping("/api/v3/orders")- DTO로 변환하여 반환 →
public List<OrderDto> orderV3() - DTO로 변환하는 것은 Ver2와 동일하게 OrderDto 를 사용하고 그 안에 OrderItemDto를 사용.
-
But, Ver2와 다르게 OrderRepository의 조회 메서드가 다름 →
List<Order> orders = orderRepository.findAllWithItem();public List<Order> findAllWithItem() { return em.createQuery("select **distinct** o from Order o" + " join fetch o.member m" + " join fetch o.delivery d" + " join fetch o.orderItems oi" + " join fetch oi.item i", Order.class) .getResultList(); }- JPA의 Entity로 조회하는 것이기에 Fetch Join 사용 가능, Fetch join을 통해 모든 연관된 테이블을 엮어서 가져오게 됨. → query 한번으로 조회 가능
- 하지만, Order와 OrderItem은 OneToMany 관계이므로 join 할 경우 OrderItem의 개수만큼 Order가 뻥튀기 됨. 즉, 중복되는 Order 데이터가 조회 되는 것. (결과 Json은 Order가 2개이더라도 join에 의해 OrderItem에 mapping된 개수인 4개로 데이터를 보내게됨)
- So! JPA의 Distinct를 통해서 중복 Entity를 제거해줘야 됨!
- JPA의 Distinct : query문을 보낼 때 물론 DB의 distinct도 실행하면서 그 결과의 Entity의 PK값이 같다면 제거 해줌. 즉, 객체 입장에서의 중복 제거를 해준다는 것 (DB의 distinct는 모든 값이 같아야 실행됨.) (결국 DB 조회 시점에 중복조회가 아닌, 중복된 데이터를 받아 온 후 memory에서 중복제거를 실행하는 것)
- 결국 Ver3는 fetch join을 통해 sql query를 하나로 줄이고, distinct를 통해 중복된 객체를 걸러서 데이터를 보내줌. (Order가 OrderItem과 OneToMany관계이기에!)
- But!! 페이징 기능 불가! -> 페이징 쿼리를 사용할 수가 없어짐 (페이징 기능을 가능케 하는 페이징 쿼리는 DB 조회 시점에서 하는 것, But JPA distinct는 받고 나서 중복제거를 함. 결국 DB 조회 시점에서 중복제거가 되지 않기에 페이징 기능을 사용할 수 없다는 것!)
- JPA distinct의 Entity 중복 제거는 SpringBootApp 단 Memory에서 실행되기에, 여기서 페이징을 실행하면 sql단에서 실행되는 것이 아닌 그 데이터를 모드 받아오고 SpringBootApp단의 memory에서 실행되게 됨. -> 의미가 없어질 뿐더러, memory 초과 야기!!
- 그럼 query 수도 줄이면서 페이징기능도 하려면 어떻게 해야 되지? → hibernate.default_batch_fetch_size 기능 이용! (Ver3.1)
[Version 3.1] “페이징 + 컬렉션 엔티티” 조회 API (hibernate.default_batch_fetch_size 이용)
@GetMapping("/api/v3.1/orders")- url을 통해 페이징에 필요한 값들을 받아와 줌. →
@RequestParam(value = "offset", defaultValue = "0") int offset,@RequestParam(value = "limit", defaultValue = "100") int limit(offset : 시작 점, limit, 끝 점 → 페이징으로 이용하는 변수들) - 가장 먼저 xToOne 관계를 가지고 있는 Entity는 그냥 Fetch Join을 통해서 받아옴. → ToOne 관계는 데이터를 뻥튀기할 위험이 없음! 즉, 데이터의 row 수가 변할 일이 없음 (데이터 뻥튀기는 xToMany 관계에서 발생)
-
페이징에 필요한 변수를 이용하여 Member와 Delivery가 join된 데이터를 페이징으로 조회 →
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);public List<Order> findAllWithMemberDelivery(int offset, int limit) { return em.createQuery("select distinct o from Order o" + " join fetch o.member m" + " join fetch o.delivery d", Order.class) .setFirstResult(offset) // 시작 점 .setMaxResults(limit) // 끝 점 .getResultList(); } - 이 상태에서 조회로직을 돌리면 쿼리는 (Order가 2개이고 각 Order당 2개의 OrderItem이 있다고 가정)
- Order들을 조회하기 위한 Query 1개 (Member와 Delivery가 Join 된 상황)
- 각 Order에 딸린 OrderItems collection을 조회하기 위한 Qeury 2개 (Order가 2개(1+1)이므로, 각 Order당 1개! → 1+N 문제 발생) (이부분이 잘 이해가지 않는다면 ver1의 참고 부분 확인!)
- 각 OrderItem의 Item을 조회하기 위한 Query 4개 (각 Order 당 2개의 OrderItem이 있는데 Item은 OrderItem당 1개임. 즉 [(1+1) + (1+1)] )
- 이런 문제를 해결하기 위해서 hibernate.default_batch_fetch_size 사용!
hibernate.default_batch_fetch_size- application.yml 에
hibernate.default_batch_fetch_size를 100으로 설정! (자동으로 한 Entity당 100건을 조회해 오겠다!) - 이 설정은 내가 조회하고자 하는 Entity와 관련된 모든 (Lazy로 설정된) Entity들을 한번에 불러옴. (자동으로 in query를 실행하는 것!)
- 즉, Order를 Member와 Delivery를 join 해서 조회했다면, 이 조회한 Order와 관련되어 있지만, join되지 않았고, Lazy로 인해 조회되지 않은 OrderItem을 자동으로 조회해줌. [ where order_item.order_id in (4,12) ] (4,12 는 현재 조회된 Order들의 id)
- 또한 OrderItem을 조회한 후, 이 OrderItem 과 관련되어 있지만 join되지 않고 Lazy로 인해 조회되지 않은 Item을 자동으로 조회해줌. [ where item.order_item_id in (5,7,13,15) ] (5,7,13,15 는 현재 조회된 OrderItem들의 id)
- 결국 Member와 Delivery가 join된 Order를 조회하는 query 한번이 나가고, Order와 관련된 OrderItems를 조회하는 query 한번이 나가고, OrderItems와 관련된 Items를 조회하는 query 한번이 나가게 되어 총 3번의 쿼리로 원하는 데이터를 얻음과 동시에 페이징기능까지 가능하게 됨. (즉, 순차적으로 조회가 필요한 Entity에 대해서 조회를 자동으로 해주는 것!!)
- 사실 페이징 기능은 orderitems (ToMany)를 join하지 않았기에 가능했던 것. (뻥튀기가 안됐음!)
- 여기서 query를 줄이기 위해
hibernate.default_batch_fetch_size를 사용해서 성능을 최적화 한 것!
[Version 4] DTO로 직접 조회하여 반환
@GetMapping("/api/v4/orders")- DTO로 직접 조회 및 반환
→
public List<OrderQueryDto> orderV4()→return orderQueryRepository.findOrderQueryDtos(); -
xToOne 관계는 그냥 이전에 했던대로 DTO로 변환해서 조회했지만, xToMany 같은 컬렉션들은 따로 직접 루프를 돌면서 DTO로 조회해줘야 함!
public List<OrderQueryDto> findOrderQueryDtos(){ List<OrderQueryDto> result = findOrders(); result.forEach(o -> { List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId()); o.setOrderItems(orderItems); }); return result; }- findOrders는 Order를 Member와 Delivery를 Join한 상태에서 OrderQueryDto로 직접 DB에서 받아오는 역할. →
select new jpabook.jpashop.repository.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status,d.address)...(OrderItem은 Collection이기에 따로 처리해 줘야 함. 즉, 현재 OrderQeuryDto의 orderItems는 채워지지 않은 상태) - 이제 각 Order를 루프로 돌면서 각 Order에 해당하는 (order_id 를 보내주며) OrderItems를 DTO 자체로 조회하여 받아옴. ->
findOrderItems(o.getOrderId());- findOrderItems는 현재 Order Id를 보내주면 그 order_id에 맞는 orderItems collection를 Item과 join 하여 orderItemDTO로 조회하여 DTO 자체로 받아와 줌. →
select new jpabook.jpashop.repository.query.OrderItemQueryDto(oi.order.id, oi.item.name, oi.orderPrice, oi.count)... where oi.order.id = :orderId ...
- findOrderItems는 현재 Order Id를 보내주면 그 order_id에 맞는 orderItems collection를 Item과 join 하여 orderItemDTO로 조회하여 DTO 자체로 받아와 줌. →
- findOrders는 Order를 Member와 Delivery를 Join한 상태에서 OrderQueryDto로 직접 DB에서 받아오는 역할. →
- 이는 DTO 자체로 조회하고 받아오는 이점이 있지만, 현재 1+N 문제가 발생하며 query 수가 많이 나오는 문제가 있음! → 최적화 필요! → Ver5!
[Version 5] JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
@GetMapping("/api/v5/orders")(query 2번으로 가져오기)- Ver 5 는 사실 JPA에서 제공하는 최적화라기 보다는 직접 메모리 단에서 코드를 통해 최적화를 진행하는 것
-
먼저 Member와 Delivery를 Join한 Order를 가져와 주고, 그 Order에 해당하는 Entity들의 id들을 뽑아온 후 그 id들을 where in query를 통해 직접 한번에 조회하는 꼴. (그 후 받아온 orderItems들을 order id에 맞게 직접 Mapping 시켜줌.)
public List<OrderQueryDto> findByDtoOpt() { // query는 한번 날리고 얻은 결과를 가지고 memory에서 각 orderitem에 맞는 order에 매핑하는 것 List<OrderQueryDto> result = findOrders(); List<Long> orderIds = result.stream().map(o -> o.getOrderId()).collect(Collectors.toList()); // order의 id들만 추출해서 저장 List<OrderItemQueryDto> orderItems = em.createQuery( "select new jpabook.jpashop.repository.query.OrderItemQueryDto(oi.order.id, oi.item.name, oi.orderPrice, oi.count) " + // order.id를 가지고 올 때, FK 값은 그 변수 자체에 있기때문에 참조하지 않고 가지고 올 수 있음 "from OrderItem oi " + "join oi.item i " + "where oi.order.id in :orderIds", OrderItemQueryDto.class) .setParameter("orderIds", orderIds) .getResultList(); // 해당 order id를 가지고 있는 모든 OrderItem을 가져오게 됨. -> query문이 한번 작성되는 것 Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream() .collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId()));// order id가 key가 되고 그에 따른 orderItemDto가 value가 됨 result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId()))); return result; }- query는 한번 날리고 얻은 결과를 가지고 memory에서 각 orderitem에 맞는 order에 매핑
- order의 id들만 추출해서 저장
- 해당 order id를 가지고 있는 모든 OrderItem을 가져오게 됨. -> query문이 한번에 모든 orderitem들을 가져오는 것
- order id가 key가 되고 그에 따른 orderItemDto가 value가 되는 orderItemMap을 생성
- 이제 각 order id에 맞는 orderItems Collection을 Mapping 시켜줌
- 직접 Memory 단에서 Mapping 시켜 query문 2번만으로 원하는 데이터를 얻을 수 있도록 최적화! (Order 1번, OrderItem 1번)
※ 조회 성능 최적화 권장 순서
- 엔티티 조회 방식으로 우선 접근 (DTO 반환)
- Fetch Join으로 Query 수 최적화 (xToOne인 경우)
- 컬렉션 최적화 (xToMany인 경우)
- 페이징 필요 X → Fetch Join Distinct 사용
- 페이징 필요 O → hibernate.default_batch_fetch_size로 최적화
- 엔티티 조회 방식으로 해결이 안된다면 DTO 조회 방식 사용
- DTO 조회 방식으로도 해결이 안된다면 NativeSQL or 스프링 JdbcTemplate 사용!
OSIV와 성능 최적화
- OSIV : Open Session In View (하이버네이트), Open EntityManager In View (JPA)
- spring.jpa.open-in-view: false (OSIV 종료, default: true)
- OSIV WARN → WARN 15204 — [ restartedMain] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
-
OSIV ON
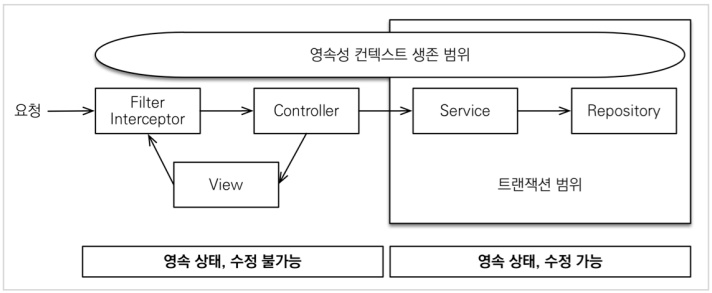
- 일단 기본적으로 Jpa의 영속성 컨텍스트는 Transactional이 시작하면 DB Connection을 가져옴 (즉, Query를 날릴 준비를 함)
- 여기서 만약 OSIV 가 켜져 있다면 Transactional이 끝나도 Connection을 끊지 않음. 즉, Transactional 밖에서도 Entity는 조회가 가능하다는 뜻 (물론 수정 및 저장 등은 Transactional 안에서만 가능)
- 즉 OSIV가 켜져있다는 것은 Transactional을 벗어나도 영속성 컨텍스트를 끝까지 살려둠. (API는 최종 반환할 때 까지, View Template은 렌더링이 다 끝나고 Response할 떄 까지.)
- 이런 설정에 의해서 우리가 Service (Transactional 존재) 밖에서도 Entity 조회 ( 지연로딩. ex, order.getMember().getName(), …) 가 가능했던 것!! 또한 VeiwTemplate에서의 Entity 조회도 가능했음! (영속성 컨텍스트가 Transactional 밖에서도 살아 있으니깐!)
- But, 이 설정은 너무 오랫동안 DB Connection을 들고 있음, 즉 실시간 트래픽이 중요한 곳에서는 이런 설정 때문에 DB Connection이 부족할 수가 있음! (Connection이 말라버린다!) → 성능에 있어서 굉장히 큰 단점으로 작용할 수 있음
-
OSIV OFF
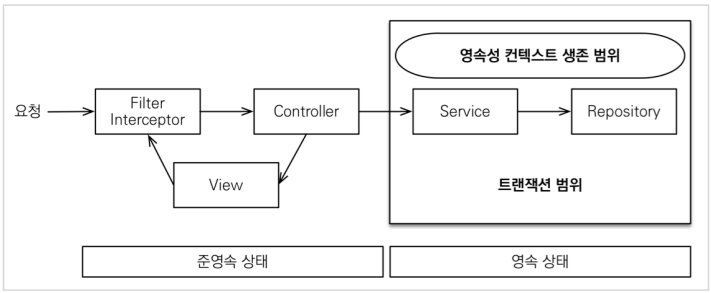
- 일단 기본적으로 Jpa의 영속성 컨텍스트는 Transactional이 시작하면 DB Connection을 가져옴 (즉, Query를 날릴 준비를 함)
- 여기서 만약 OSIV 가 꺼져 있다면 Transactional이 끝나면 Connection을 끊음. 즉, Transactional 밖에서 Entity는 조회가 분가능하다는 뜻
- DB Connection을 오래 잡지 않기 때문에 Connection이 마를 가능성이 줄어들어 좋음! (Connection을 유연하게 사용할 수 있는 장점이 있음)
- But, 모든 조회(지연로딩)를 Transactional 안에서 처리해야 된다는 큰 단점이 존재. 즉, 조회(지연로딩) 할 때 마다 Service 계층에서 모든 조회 로직을 짜고 반환 받아야 된다는 것! (fetch join 등으로 모든 관련된 애들을 service를 통해 반환 받아야지 사용가능!)
- 이는 조회 로직 용 Service를 따로 만들어서 해당 조회로직을 구현하여 Transactional 안에서 동작할 수 있도록 설정하여 하고 Controller는 이 동작 자체를 위임하는 용도로 만들어 해결할 수 있음
- 실시간 API 등 트래픽이 요구되는 서비스를 제공한다면 OSIV를 꺼줘야 함..!